ポスターセッション1 [11月5日(火)13:30-16:30]
発表一覧(レギュラー) / 発表一覧(エントリー) / ポスター配置図
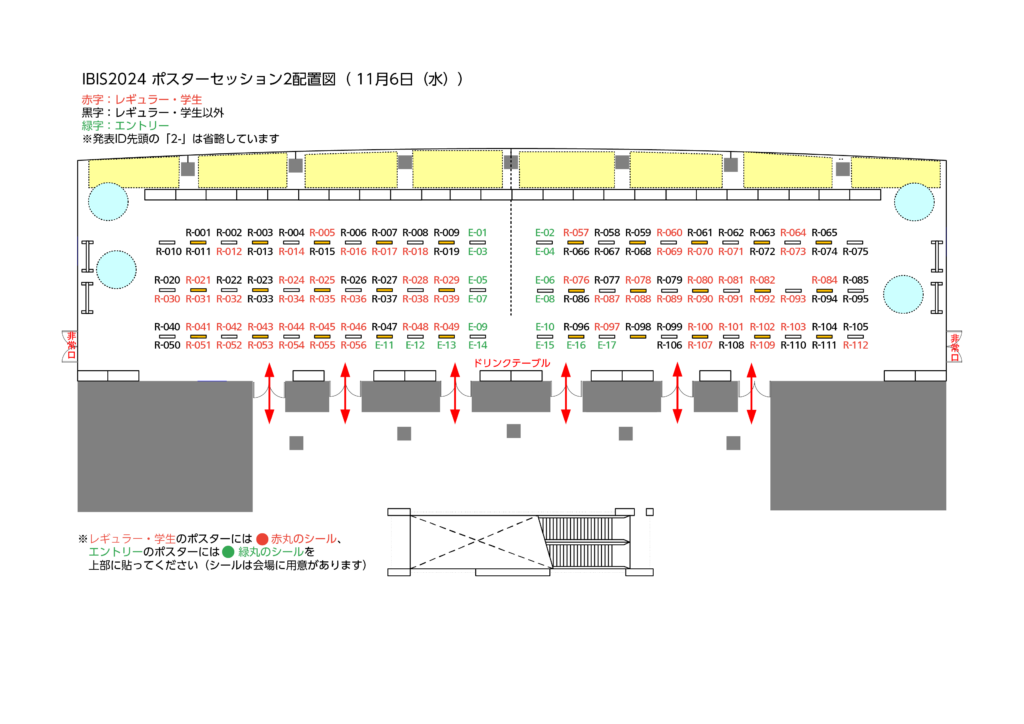
ポスターセッション2 [11月6日(水)12:30-15:30]
発表一覧(レギュラー) / 発表一覧(エントリー) / ポスター配置図
ポスターセッション1 [11月5日(火) 13:30 – 16:30] 発表一覧
レギュラー
[1-R-001] 関数自由度を持つべき密度ダイバージェンスの定式化
発表者 小林真佐大 (豊橋技術科学大学)
概要 密度のべき乗によって定義されるダイバージェンスは外れ値に対する頑健性を持ち、複数の研究によりその拡張が検討されてきた。本研究では、関数自由度を持つべき密度ダイバージェンスを非分離型ブレグマンダイバージェンスの枠組みで定式化する。この新たなダイバージェンスは、単調増加凸関数φと正のパラメータにより定義される。特定のφの選択により既存のβやγダイバージェンスおよびそれらの一般化を包含することを示す。
[1-R-002] An integrated perspective of robustness in regression through the lens of the bias-variance trade-off
発表者 奥野彰文 (統数研,理研AIP)
概要 This paper presents an integrated perspective on robustness in regression. Specifically, we examine the relationship between outlier-resistant robust estimation and robust optimization, which focuses on parameter estimation resistant to imaginary dataset-perturbations. While both are commonly regarded as robust methods, these concepts demonstrate a bias-variance trade-off, indicating that they follow roughly converse strategies.
[1-R-003] 不確かなパラメータを持つマルコフ決定過程における保証付き確率因果の探索
発表者 大浦稜平 (トヨタ自動車株式会社 未来創生センター)
概要 本研究では、不確かなパラメータを持つMDPにおける,終端状態に対する因果的な状態の集合を推定する方法を、確率上昇の原理およびパラメータサンプリングとモデル検査法に基づき提案する。得られた状態部分集合の族について、高い確信度で以下のことが成り立つ。得られた族は、終端状態への軌道を最大限カバーする確率の下限を最大化し、各状態部分集合が因果的である確率は一定値を超える。最後に,数値実験により評価を行う。
[1-R-004] 非単調量子自然勾配法の情報幾何
発表者 宮原英之 (北海道大学)
概要 自然勾配法はFisher計量を用いた最適化アルゴリズムであり、幅広いモデルに適用されている。また、その量子拡張である量子自然勾配法が近年提案され、SLD計量と呼ばれる量子Fisher計量が利用されている。SLD計量は単調性と呼ばれる基本的な性質を満たす計量であり、単調性は広く信じられている指導原理である。本研究では、あえて単調性がない計量を考えることで量子自然勾配法を高速化できることを示す。
[1-R-005] String Diagram of Optimal Transports
発表者 渡邉知樹 (国立情報学研究所), 磯部伸 (東京大学)
概要 We propose a hierarchical framework of optimal transports (OTs), namely string diagrams of OTs. Our target problem is a safety problem on string diagrams of OTs, which requires proving or disproving that the minimum transportation cost in a given string diagram of OTs is above a given threshold. We reduce the safety problem on a string diagram of OTs to that on a monolithic OT by composing cost matrices. Our novel reduction exploits an algebraic structure of cost matrices equipped with two compositions: a sequential composition and a parallel composition. We provide a novel algorithm for the safety problem on string diagrams of OTs by our reduction, and we demonstrate its efficiency and performance advantage through experiments.
[1-R-006] 決定木アンサンブルにおけるLinear Mode Connectivityの達成
発表者 加納龍一 (国立情報学研究所/総合研究大学院大学), 杉山麿人 (国立情報学研究所/総合研究大学院大学)
概要 近年ニューラルネットワークが持つ対称性を考慮しながらパラメータ間の算術処理を行うことで複数のモデルを単一のモデルへ合成する研究が盛んであり、連合学習などへの応用が期待されている。我々はニューラルネットワークと決定木アンサンブルが持つ対称性の違いを指摘し新たなアルゴリズムを開発することで、決定木アンサンブルにおいてはじめてLinear Mode Connectivityと呼ばれるモデル合成が成功する状態を達成した。
[1-R-007] Theoretical Understanding of Perturbation Learning
発表者 熊野創一郎 (東京大学), 計良宥志 (千葉大学), 山崎俊彦 (東京大学)
概要 It is not fully understood why adversarial examples can deceive neural networks and transfer between different networks. To elucidate this, several studies have hypothesized that adversarial perturbations, while appearing as noises, contain class features. This is supported by empirical evidence showing that networks trained on mislabeled adversarial examples can still generalize well to correctly labeled test samples. However, a theoretical understanding of how perturbations include class features and contribute to generalization is limited. In this study, we provide a theoretical framework for understanding learning from perturbations using a one-hidden-layer network. Our results highlight that various adversarial perturbations, even perturbations of a few pixels, contain sufficient class features for generalization. Moreover, we reveal that the network predictions when learning from perturbations matches that from standard samples except for specific regions under mild conditions.
[1-R-008] Worst-Case Offline Reinforcement Learning with Arbitrary Data Support
発表者 宮口航平 (IBM東京基礎研究所)
概要 We propose a method of the offline reinforcement learning (RL) featuring the performance guarantee without any conditions on the data support. In such circumstances, it is in general impossible to estimate or optimize for the conventional performance metric due to the distributional discrepancy between the data and the target policy. To address this issue, we employ the worst-case policy value as a new metric and constructively show that a polynomial sample complexity is attainable without any data-support conditions. Moreover, since the new metric is a generalization of the conventional one, the resulting algorithm can be used to solve the conventional offline RL problem without any modifications. In this context, our sample complexity bound can be also seen as a strict improvement on the previous bounds under the single-policy concentrability and the single-policy realizability.
[1-R-009] 使い方が類似な産業車両データによる転移学習
発表者 松浦慶伍 (産業技術総合研究所/豊田自動織機-産総研アドバンスト・ロジスティクス連携研究ラボ), 横町尚也 (産業技術総合研究所/豊田自動織機-産総研アドバンスト・ロジスティクス連携研究ラボ), 赤穂昭太郎 (産業技術総合研究所)
概要 使い方が類似な産業車両データをグルーピングする方法、及びそのグループ内でモデル回帰係数を平均的な値に転移学習することで、車両の残存寿命の予測精度を向上させた。Ridge回帰に対して16%改善し、最も予測が外れるような機台では56%改善した。
[1-R-010] Differentiable Pareto-Smoothed Weighting for High-Dimensional Heterogeneous Treatment Effect Estimation
発表者 近原鷹一 (NTT), 牛山寛生 (東京大学)
概要 患者の多数の特徴から医療処置の効果を推定する、ユーザの多数の特徴から広告配信の効果を推定するなど、高次元観察データから因果効果を推定することは多くの意思決定の場面で重要である.本研究では,極値統計分野の推定テクニックPareto smoothed importance samplingを微分可能にすることで、高次元特徴から操作変数・交絡変数・調整変数に相当する特徴表現を効果的に学習する、深層表現学習に基づく因果効果推定手法を提案する. ※AI・機械学習分野(というより因果推論分野)の難関国際会議UAI2024に採択された内容です
[1-R-011] 時間-周波数表現の対照学習による脳波解析
発表者 小峠陸登 (大阪大学), 陳崢 (大阪大学), 木村輔 (大阪大学), 松原靖子 (大阪大学), 栁澤琢史 (大阪大学), 貴島晴彦 (大阪大学), 櫻井保志 (大阪大学)
概要 本研究では、脳波データから時間-周波数表現を学習する手法を提案する。3つの対照学習損失を用い、時間・周波数表現を学習する。1エポックのファインチューニングで、てんかん発作予測や睡眠分析タスクなど様々なタスクに適応可能であり、1チャンネルのみの学習でマルチチャンネルの比較手法の精度を上回る。さらに、プライバシー保護と計算量削減のため、分割連合学習への適用も可能である。
[1-R-012] 解釈可能なパッチベースの時系列予測
発表者 吉村 玄太 (三菱電機)
概要 未来の時系列値を予測する時系列予測タスクにおいて,ニューラルネットベースの高精度な予測手法が多数提案されているが,モデルが複雑で予測根拠を人が解釈することが困難である. 本発表では,時系列をパッチ分割して変数・パッチ毎に算出した寄与度の和を予測値とすることで,どの変数・パッチが予測にどれだけ寄与したかを分解して表示できる,解釈可能性が高い時系列予測手法を提案する.
[1-R-013] 低次元構造を持つ非線形関数に対するTransformerのインコンテキスト学習能力の理論解析
発表者 宋裕進 (東京大学・理化学研究所), 西川直輝 (東京大学・理化学研究所), 大古一聡 (東京大学・理化学研究所), 鈴木大慈 (東京大学・理化学研究所), Denny Wu (New York University, Flatiron Institute, xAI)
概要 大規模言語モデルにも用いられるTransformerは,与えられた少数の例示からパターンを推測する「インコンテキスト学習 (ICL)」を可能とする.本研究ではsingle-index modelという非線形関数に対するICLを考察する.特に真の関数の分布が低次元性をもつ際に,事前学習したTransformerが低次元性に適応し,少ない例示から推論を行えることを最適化保証とともに示した.
[1-R-014] 時系列テンソルデータストリームに対する関心の拡散パターンの抽出手法
発表者 東口慎吾 (産業科学研究所), 松原靖子 (産業科学研究所), 川畑光希 (産業科学研究所), 櫻井保志 (産業科学研究所)
概要 本発表では、社会活動データストリームに対する新しい特徴抽出・将来予測手法を提案する。提案手法は、(地域、キーワード、時間)の3つの属性から構成される3階テンソルストリームから、時間変化するトレンドや季節性パターン、地域間の関心の拡散のパターンを継続的に抽出する。実データを用いた実験では、提案手法が地域間の関心の拡散のパターンを効果的に抽出し、既存手法より短い計算時間で高い将来予測精度を達成することを示す。
[1-R-015] 効率的に更新可能な学習型多次元索引
発表者 日髙楓雅 (東大), 松井勇佑 (東大)
概要 学習型多次元索引とは,機械学習モデルでデータ分布を学習し,多次元直交領域検索を古典的データ構造より高速に行う手法である.重要な課題にデータ分布の歪みによる性能低下が挙げられる.そこで我々はこの性能低下を防ぐため,内部構造を部分的に再構築するアルゴリズムの提案と,その計算量を解析した.実験結果から,既存手法と比較して最大3.9倍の高速化を達成し,更新速度の犠牲は1.7倍以内に抑えられることを示した.
[1-R-016] アニーリングと機械学習による2値圧縮センシングの信号復元相転移
発表者 Huang Xiaoxin (東北大学情報), 大関真之 (東北大学情報/東京科学大学物理/シグマアイ)
概要 2値圧縮センシング問題をQUBO形式で定式化し、アニーリングで解く方法が提案されているが、正則化パラメータλの適切な設定が不明で、信号の再構成精度に大きな影響を与え、数値実験と理論的な解析と一致しない問題がある。 本研究では、機械学習を用いた適応的な正則化手法を提案し、シミュレーテッドアニーリングと量子アニーリングで最適化を行い、従来手法による結果などを比較して考察する。
[1-R-017] 保存型・階層型グラフニューラルネットワークによる物理現象の学習
発表者 堀江正信 (株式会社RICOS), 三目直登 (筑波大学)
概要 物理現象における多様な状態を効率的に学習するためには現象の局所性を利用できる GNN (グラフニューラルネットワーク) を用いるのが効果的である。しかしながら、GNN はその局所性ゆえに現象の大域的な特徴を捉えにくいという欠点がある。そこで、拡大・縮小について物理現象の対称性を満たす発表者らの既存研究 [Horie & Mitsume. ICML 2024] をもとに、それを階層化することでさまざまなスケールの相互作用を考慮する方法について議論する。
[1-R-018] Transformers are Minimax Optimal Nonparametric In-Context Learners
発表者 Juno Kim (東京大学・理研), Tai Nakamaki (東京大学), Taiji Suzuki (東京大学・理研)
概要 In-context learning (ICL) of large language models has proven to be a surprisingly effective method of learning a new task from only a few demonstrative examples. In this paper, we shed light on the efficacy of ICL from the viewpoint of statistical learning theory. We develop approximation and generalization error analyses for a transformer model composed of a deep neural network and one linear attention layer, pretrained on nonparametric regression tasks sampled from general function spaces including the Besov space and piecewise gamma-smooth class. In particular, we show that sufficiently trained transformers can achieve — and even improve upon — the minimax optimal estimation risk in context by encoding the most relevant basis representations during pretraining. Our analysis extends to high-dimensional or sequential data and distinguishes the pretraining and in-context generalization gaps, establishing upper and lower bounds w.r.t. both the number of tasks and in-context examples. These findings shed light on the effectiveness of few-shot prompting and the roles of task diversity and representation learning for ICL.
[1-R-019] 逆プロンプトを用いたコールドスタート推薦
発表者 草野元紀 (NEC)
概要 新商品などの教師データがなくて予測が困難になるコールドスタート推薦に取り組む。この問題は、LLMを用いることで効率的に解決できるが、推論にかかる処理速度とAPI費用が運用上の大きな課題となる。そこで、LLMを推論器ではなくデータ拡張器として活用することを提案する。コアアイディアは、ユーザが商品を好きかどうかを予測させる従来のプロンプトを、ユーザが好きそうな商品を生成させるプロンプトに変換したことである。
[1-R-020] 研究助成ネットワークの高次コミュニティ構造の推定と可視化
発表者 中嶋一貴 (東京都立大学), 宇野毅明 (国立情報学研究所)
概要 3 つ以上の研究機関が 1 つの共同研究課題を実施することは珍しくなく,そのような一連の共同研究課題はハイパーグラフとして表現できる.本研究では,確率的ブロックモデルと次元削減法を組み合わせて,研究助成ネットワークの高次コミュニティ構造を分析する.研究機関間の共同研究関係は強力なコミュニティ構造を示さないが,研究機関とその研究代表者の分野のペア間の共同研究関係は顕著なコミュニティ構造を示す.
[1-R-021] LINE NEWSにおけるユーザーの消費アイテム多様性と離脱率予測
発表者 曽弘博 (LINEヤフー株式会社), 張天翔 (LINEヤフー株式会社), 和地瞭良 (LINEヤフー株式会社)
概要 近年、「多様なアイテムを消費するユーザーは、サービスをより長期的に利用する傾向がある」ことを示した研究が複数発表されている。本発表では、LINE newsのログを利用し、ユーザーが閲覧した記事の多様性と、ユーザーの長期的な振る舞いの関係を調べた。また、多様性スコアを特徴量に加えることにより、継続利用率予測の改善を試みた結果を紹介する。
[1-R-022] Transformerを用いた量子回路生成と組合せ最適化問題への応用
発表者 南俊匠 (産総研), 中路紘平 (NVIDIA/トロント大), 鈴木洋一 (産総研), 門脇正史 (産総研/DENSO)
概要 量子コンピュータによる情報処理は、古典コンピュータでは計算困難な大規模問題を超高速に解決できる可能性があり、新たな計算パラダイムとして注目を集めている。しかし、量子計算を実行するための量子回路の設計には高度な専門知識が要求される。本研究では、この回路設計プロセスの簡略化を目指し、Transformerを用いた量子回路の自動生成手法を提案する。特に組合せ最適化問題を対象にその有用性を検証する。
[1-R-023] 物理深層学習を用いたスロー地震発生域の摩擦特性空間分布の推定
発表者 福嶋陸斗 (東北大学、京都大学、現Stanford大学), 加納将行 (東北大学), 平原和朗 (理研、香川大学), 大谷真紀子 (京都大学), Kyungjae Im (Caltech), Jean-Philippe Avouac (Caltech)
概要 物理深層学習(PINN)を用いて、地殻変動データからプレート沈み込み帯の断層すべりの形態を規定する摩擦特性の物理パラメータの空間分布を逆推定する手法を開発した。
[1-R-024] 行動が連続値の場合におけるエクストリームラーニングマシンを用いた強化学習
発表者 小松尚登 (滋賀大学)
概要 エクストリームラーニングマシン(ELM)は多層パーセプトロンにおいて出力結合重みのみを学習する機械学習手法であり、計算コストの軽さなどの特長から注目されている。 このELMを用いた強化学習の手法としてはJ. Liu et al. 2021などの先行研究が存在するが、これは行動が離散的な場合を前提としていた。本研究では、行動が連続値の場合の強化学習をELMによって実装する。
[1-R-025] 因果推論に基づく反実仮想設定でのユーザマッチングの性能推定とモデル学習
発表者 河村 和紀 (ソニーグループ), 宇田川 拓麻 (ソニーグループ), 舘野 啓 (ソニーグループ)
概要 マッチングはユーザ間のインタラクションが発生するプラットフォームで重要であるが,各サービスの目的や運用方針によって問題設定が異なるため,適切な手法の選定が困難である.本研究では,マッチング問題を包括的に分類し,各プラットフォームに適した解決策の選定を可能にする.また,既存手法に共通する選択バイアスの問題に対し,因果推論を用いた反実仮想相互推薦システムを提案する.
[1-R-026] 局所地域から全球スケールに適用可能な地殻ブロックの同定法:測地学・微分幾何学・データ科学の交差点
発表者 矢野恵佑 (統計数理研究所), 高橋温志 (理化学研究所), 加納将行 (東北大学)
概要 高密度のGlobal Navigation Satellite System (GNSS)観測データの拡充により,プレート運動の詳細な様子が明らかになってきた.近年,適切な地殻ブロック構造を仮定するための客観的な同定方法が提案されてきている.本講演では,微分幾何学に基づき新たな地殻ブロックの同定法を提案しその適用例を紹介する.
[1-R-027] 1段階レプリカ対称性の破れを考慮した非凸性アニーリング
発表者 坂田綾香 (統計数理研究所), 小渕智之 (京都大学)
概要 非凸性アニーリングとは、非凸制約のパラメータを調節しながら推論を行う方法を指す。これまで著者はSCAD, MCPと呼ばれる非凸制約最小化問題において、レプリカ対称性仮定の下での非凸性アニーリングを提案してきたが、アニーリング限界が存在していた。本発表では、1段階レプリカ対称性の破れを考慮することで非凸性アニーリングの性能が改善される可能性について説明する。
[1-R-028] A system of evolution variational inequalities on metric spaces and an exponential convergence of gradient descent ascent flows on Wasserstein space
発表者 磯部伸 (東京大学), 下山翔 (東京大学)
概要 The theory of gradient flow on metric spaces can elucidate optimization dynamics in deep learning on Wasserstein space, a metric space of probability distributions. In particular, the evolution variational inequality (EVI) plays an important role in the analysis of the asymptotic behavior of the dynamics. On the other hand, the optimization dynamics of GAN and multi-agent reinforcement learning can be modeled by a system of differential equations on Wasserstein space called gradient (descent) and ascent flows. However, the lack of a theory corresponding to the system makes it difficult to analyze the asymptotic behavior of these flows. Therefore, we prove the existence and non-expansiveness of a system of EVIs on metric space. Furthermore, we apply this theory to prove the exponential convergence of mean-field Langevin dynamics to equilibrium for two-player zero-sum games with entropy-regularized convex-concave rewards.
[1-R-029] 等価な再定式化に基づく least trimmed squares の高速数値解法
発表者 柳下翔太郎 (統計数理研究所)
概要 Least trimmed squares (LTS) は二乗誤差を総和の代わりに小さいほうからいくつか足したものを損失関数として用いるロバスト回帰の方法である.最も頻繁に用いられる数値解法は,スパース推定を同時に考慮した際に顕著に遅くなる.本発表ではLTSを等価に再定式化することによって,近接勾配法を用いて効率的に解くことを提案する.
[1-R-030] Analysis of High-dimensional Gaussian Labeled-unlabeled Mixture Model via Message-passing Algorithm
発表者 Xiaosi Gu (Kyoto University, Graduate School of Informatics), Tomoyuki Obuchi (Kyoto University, Graduate School of Informatics)
概要 We study the high-dimensional Gaussian labeled-unlabeled classification problem using a message-passing algorithm, namely AMP, for both the regularized maximum likelihood estimation (RMLE) and Bayesian approach estimation. We derive a comprehensive phase diagram, revealing insights into the behavior of the two estimation methods. Our results demonstrate that the optimal RMLE closely approximates the Bayes-optimal result.
[1-R-031] 凸係数による適正損失の特徴づけ
発表者 包 含 (京都大学)
概要 適正損失(proper loss)は分類問題や二部ランキングなど幅広い予測問題に用いられる損失関数であり、交差エントロピー損失はその一例である。一般的な流れでは、まず適正損失を最適化し得られた確率予測を用いてプラグイン推定を構成する。そのため、得られる確率予測の良さの定量化は重要である。本研究では、適正損失に紐づく「一般化エントロピー関数」の凸係数が推定誤差上界を特徴づけることを示す。
[1-R-032] 勾配クリッピング付き勾配法のためのパラメータフリー最適化手法
発表者 竹澤祐貴 (京都大学/OIST), 包含 (京都大学/OIST), 佐藤竜馬 (NII), 丹羽健太 (NTT), 山田誠 (OIST)
概要 勾配法はハイパーパラメータの設定に敏感である。そのため、グリッドサーチ等を用いて慎重 に調整する必要があるが、これには非常に時間がかかる。近年ハイパーパラメータを学習中に自動 で調整するパラメータフリー手法が研究されている。しかし、既存の研究では学習率以外のハイパー パラメータに関する手法は研究されていない。本研究では、勾配クリッピング付き勾配法のためのパ ラメータフリー手法を研究し、L-平滑かつ(L0,L1)-平滑な損失関数に対してクリッピング付き勾配法と 同様にLに漸近的に依存しない収束率で収束するパラメータフリー手法を提案する。
[1-R-033] 線形モデルにおける十分統計量を用いた継続学習
発表者 村山太朗 (株式会社デンソー), 李翰柱 (株式会社デンソー), 小嶋信矢 (株式会社デンソー)
概要 継続学習では、破滅的忘却を防ぐために学習済みデータを全て保持しておく必要があり、学習コスト増大が問題となっている。本研究では、学習済みデータから算出した十分統計量のみを保持することで、学習コストを一定に保ったまま忘却を回避(または抑制)する手法を提案する。線形回帰、SVM、およびカーネルモデルにおいて数値実験を行い、有効性を示す。
[1-R-034] シミュレータと実機の並列運転による高効率なパラメータ調整手法の検討
発表者 伊藤 凜 (三菱電機株式会社)
概要 製品の開発や保守における制御パラメータ等の調整は、高い性能を実現するために重要な役割を持つ。通常は実装置を運転し、その性能を確認しながらパラメータ調整を行うが、実装置の性能を評価するには長い時間を要することが多い。本研究では装置の挙動を模擬したシミュレータを用い、装置と同時並行で運転することによりパラメータ調整の効率を上げる手法について検討する。
[1-R-035] モデルフリーLasso型正則化学習法の提案
発表者 山﨑遼也 (一橋大), 田中利幸 (京大)
概要 回帰や分類などの予測タスクにおいて、目的変数のふるまいを説明するのに不必要な特徴が説明変数に含まれ、両変数間に非線形の分布構造が存在する場合に、予測性能の高いモデルを得ることを目的とした学習法を提案する。提案法は、Lasso回帰のような正則化学習法のモデルフリー拡張と解釈でき、任意の予測モデルと組み合わせて使用できる。予測モデルにニューラルネットワークを用いた場合の数値実験でその有効性を確認した。
[1-R-036] Speed-accuracy trade-off for the diffusion models: Wisdom from nonequilibrium thermodynamics and optimal transport
発表者 池田滉太郎 (東京大学), 宇田智哉 (東京大学), 岡野原大輔 (Preferred Networks), 伊藤創祐 (東京大学)
概要 拡散モデルに用いられる拡散過程は非平衡熱力学においても議論されてきた。本研究では拡散モデルと非平衡熱力学の関係を整理し、二者間のアナロジーを通じて拡散モデルのデータ生成における速度と精度のトレードオフ関係を導出した。我々の結果は拡散モデルの順過程におけるエントロピー生成率がデータ生成精度に影響することを表し、また最適輸送理論的なコストの最小化を行うことで精度の高いデータ生成が行えることを示唆する。
[1-R-037] GeoBeta Flow Matching
発表者 池田滉太郎 (東京大学), 小山雅典 (Preferred Networks), 林浩平 (Preferred Networks), 福水健次 (統計数理研究所)
概要 生成モデルの一つであるflow matching (FM) においてラベルが連続値をとる状況で条件付き生成を行う場合、既存の手法では条件の一致性が下がってしまう。我々は最近発表されたconditional optimal transport FMを基に条件ラベルが持つ幾何構造を考慮したモデルを用いて、条件の一致性を向上できることを見出した。また人口及び実データを用いて既存手法との比較を行った。
[1-R-038] Adaptive Generalized Neyman Allocation: Local Asymptotic Minimax Optimal Best Arm Identification
発表者 Masahiro Kato (Mizuho-DL Financial Technology Co., Ltd.)
概要 This study investigates a locally asymptotic minimax optimal strategy for fixed-budget best arm identification (BAI). Given multiple arms, we consider an adaptive experiment where, in each round, an arm is drawn, and the best arm is estimated at the end. Our objective is to design a strategy that minimizes the probability of misidentifying the best arm. For this setting, we propose the Adaptive Generalized Neyman Allocation (AGNA) strategy and demonstrate that its worst-case upper bound for the probability of misidentification matches the worst-case lower bound in the small-gap regime, where the gap between the expected outcomes of the best and suboptimal arms approaches zero. Our strategy generalizes the Neyman allocation, which draws each arm according to the ratio of its standard deviation and is known to be asymptotically optimal in two-armed bandits (Neyman, 1934; Kaufmann et al., 2016). Our result addresses a longstanding open question regarding the existence of asymptotically optimal strategies in fixed-budget BAI.
[1-R-039] On the Linear Structure of Nonlinear Sequence Models
発表者 Stefano Massaroli (RIKEN AiP), Taiji Suzuki (The University of Tokyo, RIKEN AiP)
概要 In the present work we provide a comprehensive theoretical framework for understanding and analyzing the computational primitives that form the foundation of modern deep learning architectures, particularly in the domain of sequence processing. We introduce the concept of Linear Input-Varying (LIV) systems, a class of nonlinear operators that can be expressed as adaptive linear operators whose actions are determined by the input itself. This framework unifies and subsumes a wide range of existing computational units in deep learning, providing a systematic approach to exploring the design space of architectures. Our analysis focuses on three key aspects of LIV systems: token-mixing structure, channel-mixing structure, and featurization. We examine how these aspects influence the computational efficiency, expressiveness, and hardware compatibility of deep learning models. This work bridges the gap between the theoretical expressiveness of nonlinear systems and the practical constraints of hardware acceleration, explaining the convergence of deep learning towards computational units that balance nonlinear expressivity with the efficiency of matrix-vector operations. Our findings provide insights into the design of more efficient and powerful deep learning architectures, potentially guiding future research in both theoretical and applied machine learning. By formalizing the study of LIV systems, we contribute a new theoretical tool for understanding the capabilities and limitations of deep learning models, particularly in processing variable-length sequences. This framework not only elucidates the current state of deep learning primitives but also opens avenues for developing novel architectures that can better leverage modern hardware capabilities while maintaining the flexibility and expressiveness required for complex tasks in artificial intelligence and signal processing.
[1-R-040] レベル集合推定のためのランダム化に基づく適応的意思決定アルゴリズム
発表者 稲津佑 (名古屋工業大学), 竹野思温 (名古屋大学, 理研AIP), 沓掛健太朗 (名古屋大学), 竹内一郎 (名古屋大学, 理研AIP)
概要 本研究では, ブラックボックス関数の値が与えられた閾値以上(以下)となる領域を同定するレベル集合推定問題を検討する.ガウス過程を用いてブラックボックス関数に対する妥当な信用区間を構築し, 信用区間の幅を調整するパラメータを適切な確率分布からサンプルするランダム化を行うことで,理論的妥当性と実践的性能を両立する新しい適応的意思決定アルゴリズムを提案する.
[1-R-041] マルチインスタンス学習に帰着可能な問題の特徴づけ
発表者 末廣大貴 (九州大学,理研AIP), 瀧本英二 (九州大学)
概要 マルチクラス学習,マルチラベル学習,補ラベル学習など,多様な学習問題がマルチインスタンス学習(MIL)に帰着可能であることがわかっているが,どのような学習問題がMILに帰着可能か,その特徴付けは未だ明らかにされていない.本研究では,MIL帰着可能な問題の特徴づけを与えるための定式化,帰着の枠組みについて紹介する.
[1-R-042] 共変量の選択による平均処置効果の効率的な推定のための能動的適応的実験計画
発表者 井口 亮 (みずほ第一フィナンシャルテクノロジー), 大賀 晃弘 (みずほ第一フィナンシャルテクノロジー), 小松原 航 (みずほ第一フィナンシャルテクノロジー), 加藤 真大 (みずほ第一フィナンシャルテクノロジー)
概要 本研究では,平均処置効果(ATE)の効率的な推定を目的とした適応的な実験を設計する.実験者は,逐次的に,過去の実験結果に基づいて被験者をサンプリングして処置の割り当てを行い,その結果をすぐに観察することができるとする.実験終了時に,実験者は集めたデータを用いてATEを推定する.実験者の目的は,漸近分散がより小さなATEを推定することである.既存の研究では,処置割当確率である傾向スコアだけを適応的に最適化する実験設計が行われてきたが,本研究では,このアプローチの一般化として,被験者の特徴である共変量密度と傾向スコアの両方を最適化することで,漸近分散を最小化する方法を提案する.
[1-R-043] LayeredLiNGAM: A Practical and Fast Method for Learning a Linear Non-gaussian Structural Equation Model
発表者 鈴木浩史 (富士通株式会社)
概要 LiNGAMは変数間の因果関係を分析する構造方程式モデルの一種である。その代表的な学習法DirectLiNGAMは巧みに変数の因果的順序を推定するが、計算量が変数数の3乗に比例し、大規模データへの適用が難しい。本研究では、因果グラフの”層”に着目して計算量を改善したLayeredLiNGAMを提案する。※機械学習・データマイニング分野の国際会議 ECML PKDD 2024 に採択された内容です。
[1-R-044] 線形構造的因果モデルによる根本原因・構造変化分析
発表者 高田正彬 (株式会社東芝), 新垣隆生 (株式会社東芝)
概要 根本原因分析は,観測された結果の背後にある根本的な原因をデータに基づいて特定する方法論であり,問題の理解や対策の検討に役立つ.従来のShapley値ベースの方法では,煩雑な計算が必要であり,因果構造の変化が無視されていた.本研究では,線形構造的因果モデル(SCM)を用いて,シンプルかつ構造変化を考慮した根本原因分析手法を提案する.これにより,効率的・正確に根本原因を特定することが可能となる.
[1-R-045] Synchronization behind Learning in Periodic Zero-Sum Games Triggers Divergence from Nash equilibrium
発表者 藤本悠雅 (サイバーエージェント), 蟻生開人 (サイバーエージェント), 阿部拳之 (サイバーエージェント)
概要 Learning in zero-sum games studies a situation where multiple agents competitively learn their strategy. In such multi-agent learning, we often see that the strategies cycle around their optimum, i.e., Nash equilibrium. When a game periodically varies (called a “periodic” game), however, the Nash equilibrium moves generically. How learning dynamics behave in such periodic games is of interest but still unclear. Interestingly, we discover that the behavior is highly dependent on the relationship between the two speeds at which the game changes and at which players learn. We observe that when these two speeds synchronize, the learning dynamics diverge, and their time-average does not converge. Otherwise, the learning dynamics draw complicated cycles, but their time-average converges. Under some assumptions introduced for the dynamical systems analysis, we prove that this behavior occurs. Furthermore, our experiments observe this behavior even if removing these assumptions. This study discovers a novel phenomenon, i.e., synchronization, and gains insight widely applicable to learning in periodic games.
[1-R-046] Partitioned Learned Bloom Filter の高速構築とその理論的保証
発表者 佐藤 篤樹 (東京大学), 松井 勇佑 (東京大学)
概要 PLBFは優れたメモリ効率をもつ学習型Bloom Filterであるが、その構築には高い計算量を要する。本研究ではPLBFの構築を高速化する3つの手法を提案した。これらの手法はPLBFよりも低い計算量で構築可能であり、同じもしく近いメモリ効率を持つことを理論的に保証できる。実験では、提案手法がPLBFの最大788倍程度高速に構築でき、PLBFとほぼ同じメモリ効率を持つことを示した。
[1-R-047] ANMとRECIを選択的に使い分けるswitch-SEMの提案
発表者 蓮池正晴 (株式会社ジェイテクト), 宮嵜伊弦 (株式会社豊田中央研究所)
概要 LiNGAMに代表される構造方程式モデリングはデータに対して何らかの仮定を置く。仮定の緩和に関する研究は盛んに行われているが、モデル選択的なアプローチの研究はあまりされていない。本発表では、ノイズ(残差)と説明変数の独立検定の結果に基づきANMとRECIを選択的に使い分けるswitch-SEMを提案する。
[1-R-048] マッチング問題への量子アルゴリズムの応用
発表者 権業慎也 (デンソーアイティラボラトリ), 石川康太 (デンソーアイティラボラトリ)
概要 量子ゲートマシンでグラフ・マッチング問題を解くアルゴリズムについて発表する。
[1-R-049] バッチエフェクトに適応的ながん種分類モデルのベンチマーク評価
発表者 四辻嵩直 (株式会社東芝), 高田正彬 (株式会社東芝), 李根 (株式会社東芝), 藤澤洋徳 (統計数理研究所)
概要 生体遺伝子測定データの分析において、測定装置や測定試薬の差などによるバッチエフェクトは、生物学的要因以外の変動を引き起こし、疾患分類モデルの精度を低下させる可能性がある。本発表では、バッチエフェクトの影響を抑制して安定した分類性能を維持するタスクを検討し、データセットを用意して既存手法を適用するベンチマーク評価を行う。
[1-R-050] A neural dynamic mode decomposition methodology with generative AI techniques towards a transparent MRV measure going across scale-gaps for sutainable decision making on the chaotic dynamical earth system
発表者 新井宏徳 (大阪大学), 河原吉伸 (大阪大学), ThuyLeToan (仏国宇宙生物圏研究所), 大吉慶 (JAXA), 竹内渉 (東京大学), SonVNghiem (米国NASA-JPL), 市川香 (九州大学), mehrez zribi (仏国宇宙生物圏研究所), KimThuNguyen (越国クーロン稲研究所), NguyenTheCuong (越国クーロン稲研究所), Thach NgocTran (越国クーロン稲研究所), NhutThiMinh (国際稲研究所), TranThiCamNhung (国際稲研究所), HuuDiemHaNguyen (国際稲研究所), 麓多門 (農研機構), 犬伏和之 (千葉大学), LamDaoNguyen (越国ホーチミン宇宙センター), 島ノ江憲剛 (九州大学), HungVanNguyen (国際稲研究所), 祖父江真一 (JAXA)
概要 In terms of GHG accounting, Monitoring, Reporting and Verification (MRV) systems with high transparency is essential to formulate Nationally Determined Contributions. The presenters have been working to establish efficient/transparent MRV system based on a neural dynamic mode decomposition measure which is designed for assimilating multi-scale observation in the chaotic dynamical earth system. By synthesizing multipoint & long-term field observation data, satellite remote sensing data in local/regional/global scales simultaneously. To provide the transparency, we developed a unique grid-wise Grad-CAM technique which can work not only as its attention map, but also as the regularizer of the network itself. We succesfully demonstrated to improve the prediction accuracy by using the Grad-CAM as the droppingconnecting criteria on the model grid-wise. Furthermore, we also proposed a semi-hybrid method of a quantizing variational auto-encoding method and a diffusion modelling method, which successfully converted the large-scale slow chaotic mode into intermitten forcings’ space. This space was efficiently generated as the base in which the koopman space to be embeded. The diffusion model type skip connection scheme enabled a latent variables to consists of smaller-scales faster modes individually to implement multi-resolution DMD with a chaos synchronization scheme naturally and locally. Finally, we will discuss the direction of AI technology development to support decision making of internationally diverse stakeholders.
[1-R-051] 極値統計学を用いた外観検査の閾値決定方法の提案
発表者 中村 ちから (株式会社アイシン), 戸田 昌孝 (株式会社アイシン), 坂本 昌之 (株式会社アドヴィックス), 鈴村 徳宏 (株式会社アドヴィックス), 戸田 裕之 (株式会社アドヴィックス)
概要 品質管理において、3σ法は異常検出の閾値として最も用いられる手法の一つである。3σ法はデータが正規分布に従う前提のもとで有効な手法である。しかし、実際の工程では必ずしも正規分布とは限らないデータを扱う必要があり、その場合には3σ法の持つ統計的解釈が失われてしまう。本発表では、極値統計学を用いて従来の3σ法の課題を解決する新たな閾値決定方法を提案する。
[1-R-052] Filtered Direct Preference Optimization: 選好データセットの質に基づくフィルタリング手法の提案
発表者 坂本 充生 (株式会社サイバーエージェント), 森村 哲郎 (株式会社サイバーエージェント), 陣内 佑 (株式会社サイバーエージェント), 阿部 拳之 (株式会社サイバーエージェント), 蟻生 開人 (株式会社サイバーエージェント)
概要 人間のフィードバックからの強化学習(RLHF)は,言語モデルを人間の好みに調整する上で重要である.データセットの質の重要性は認識されているが,RLHFにおける影響の調査は限られている.本論文は,Direct Preference Optimization(DPO)における選好データセットの質に注目し,応答文の質がDPOで訓練されたモデルの性能に大きな影響を与えることを確認する.この問題に対して,DPOの拡張版であるFiltered DPO(fDPO)を提案する.fDPOは,DPOの訓練中に選好データセットの応答文の質を測るために報酬モデルを使用し,学習中のモデルが生成する文と比べて質の低い文を破棄する.実験の結果,fDPOがDPOと比較してモデルの性能を向上させることを示す.
[1-R-053] A multi-armed bandit approach to mechanism design
発表者 恐神貴行 (IBM Research), 木下 裕太 (東京大学), Segev Wasserkrug (IBM Research)
概要 A popular approach of automated mechanism design is to formulate a linear program (LP) whose solution gives a mechanism with desirable properties. We analytically derive a class of optimal solutions for such an LP that gives mechanisms achieving standard properties of efficiency, incentive compatibility, strong budget balance (SBB), and individual rationality (IR), where SBB and IR are satisfied in expectation. Notably, our analytical solutions are represented by an exponentially smaller number of essential variables than the original variables of LP. The analytical solutions, however, involve a term whose exact evaluation requires solving a certain optimization problem exponentially many times as the number of players grows. We thus evaluate this term by modeling it as the problem of estimating the mean reward of the best arm in multi-armed bandit (MAB), propose a Probably and Approximately Correct estimator, and prove its asymptotic optimality by establishing a lower bound on its sample complexity. This MAB approach reduces the number of times the optimization problem is solved from exponential to linear. Numerical experiments show that the proposed approach finds mechanisms that are guaranteed to achieve desirable properties with high probability for environments with up to 128 players, which substantially improves upon the prior work.
[1-R-054] Compositional Simulation-based Inference for Time Series
発表者 Manuel Gloeckler (University of Tubingen), 豊田 祥史 (九州大学), 福水健次 (統計数理研究所), Jakob H. Macke (University of Tubingen, Max Planck Institute for Intelligent Systems)
概要 Simulation-based Inference(SBI)とはブラックボックスシミュレータのパラメータ推論法である.深層生成モデルを利用した高次元問題へスケール可能なSBIの創設が試みられているが, 時系列シミュレーションへ適用する際の学習コストは高い現状にある. 本研究では, シミュレータの時系列を利用し,低学習コストかつ長い時系列観測に対応可能な深層生成SBIの確立を目指す.
[1-R-055] Learning Neural Strategy-Proof Matching Mechanism from Examples
発表者 丸尾亮太 (京都大学大学院), 竹内孝 (京都大学大学院), 鹿島久嗣 (京都大学大学院)
概要 Designing effective two-sided matching mechanisms is a major problem in mechanism design, and the goodness of matching cannot always be formulated. The existing work addresses this issue by searching over a parameterized family of mechanisms with certain properties by learning to fit a human-crafted dataset containing examples of preference profiles and matching results. However, this approach does not consider a strategy-proof mechanism, implicitly assumes the number of agents to be a constant, and does not consider the public contextual information of the agents. In this paper, we propose a new parametric family of strategy-proof matching mechanisms by extending the serial dictatorship (SD). We develop a novel attention-based neural network called NeuralSD, which can learn a strategy-proof mechanism from a human-crafted dataset containing public contextual information. NeuralSD is constructed by tensor operations that make SD differentiable and learns a parameterized mechanism by estimating an order of SD from the contextual information. We conducted experiments to learn a strategy-proof matching from matching examples with different numbers of agents. We demonstrated that our method shows the superiority of learning with context-awareness over a baseline in terms of regression performance and other metrics.
[1-R-056] State Space Models are Provably Comparable to Transformers in Dynamic Token Selection
発表者 西川 直輝 (東京大学, 理研AIP), 鈴木 大慈 (東京大学, 理研AIP)
概要 S4やMambaなど,状態空間モデルを基にした深層学習手法は,計算量がTransformerと比べて小さいという利点をもつ.本研究では,状態空間モデルの能力を理論的に明らかにするため,Transformerの重要な能力である「入力に適応的な特徴選択」を状態空間モデルが模倣できることを示す.具体例として,2つの人工タスク,およびノンパラメトリック回帰において,状態空間モデルがTransformerに匹敵することを示す.
[1-R-057] 拡散モデルの相転移現象を幾何学的に解き明かす!
発表者 矢口 真那斗 (東京大学), 坂本 航太郎 (東京大学), 坂本 龍亮 (北海道大学), 田邊 真郷 (北海道大学), 赤川 正朋 (北海道大学), 林 祐輔 (AI Alignment Network), 嘉陽 海渡 (北海道大学), 鈴木 雅大 (東京大学), 松尾 豊 (東京大学)
概要 拡散モデルの生成過程においてデータの特徴が最終段階において突如出現する相転移現象が知られている.本研究では相転移現象を幾何学的視点から明らかにする.特に,データ多様体の管状近傍の半径の上限として定まる単射半径が相転移現象と密接に関連していることを,理論および実験的に示す.我々の研究によって得られる知見は,拡散モデルにおける効率的かつ制御可能なサンプリング手法の確立に寄与するものとして期待できる.
[1-R-058] マルコフ決定過程における良方策検定手法の提案
発表者 蟻生開人 (サイバーエージェント), Po-An Wang (KTH), 阿部 拳之 (サイバーエージェント), Alexandre Proutiere (KTH)
概要 本研究では、マルコフ決定過程における特定の方策の価値関数が与えられた閾値を超えるか否かを固定信頼度で判定する問題を考察する。最適な判定基準は最適化問題として定義されるが、その求解法は未だ明らかにされていない。本研究では、この最適化問題の求解法を強化学習の方策勾配法の知見を拡張した手法として提案する。
[1-R-059] Automated Theorem Proving by HyperTree Proof Search with Retrieval-Augmented Tactic Generator
発表者 園田翔 (理化学研究所), 恩田直登 (OMRON SINIC X), 塚本慧 (東京大学), 内山史也 (東京大学), 三内顕義 (京都大学), 熊谷亘 (OMRON SINIC X)
概要 We propose an automated theorem prover (ATP) based on the HyperTree Proof Search (HTPS) enhanced by retrieval-augmented tactic generator (ReProver).
[1-R-060] 同時群同変モデルの表現論的な構成的普遍近似定理
発表者 園田翔 (理研), 橋本悠香 (NTT, 理研), 石川勲 (愛媛大, 理研), 池田正弘 (理研)
概要 同時群同変モデルとは,全結合・深層ニューラルネット(同時群同変だが群同変ではない)や群同変ネットワーク(同時群同変かつ群同変である)を含む広い学習モデルのクラスである.これらの学習モデルに作用する群の誘導表現が既約であるとき,学習モデルが普遍近似性(L2稠密性)をもつことを示した.紙面に余裕があれば汎化誤差評価との関係も議論する.
[1-R-061] 傾向スコア関数を用いた類似する処置の統合と因果効果推定
発表者 吉川剛平 (九州大学, NTTデータ数理システム), 川野秀一 (九州大学)
概要 複数の処置に対する因果効果推定をする際、正値性違反の対処や解釈の難しさが課題として挙げられる。この課題に対し本研究では、傾向スコア関数を用いて類似した処置を統合する理論的な枠組みと方法論を提案する。類似した冗長な処置を統合することにより、正値性違反を緩和し、因果効果の解釈を簡潔することができる。数値実験を通して、理論の有用性を検証する。
[1-R-062] 探索進捗率に基づく終了判定可能なベイズ最適化
発表者 増井秀之 (三菱電機株式会社), 長澤廉師 (三菱電機株式会社), 中根滉稀 (三菱電機株式会社), 烏山昌幸 (名古屋工業大学), 稲津佑 (名古屋工業大学)
概要 ベイズ最適化は少ない探索回数でブラックボックス関数の最適化が可能な手法として知られている。しかし、大域的最適解が得られたかどうかを知る術がなく、探索を終了する判断の難しさが実応用上の大きな課題となっている。本発表では、大域的最適解が存在する可能性のある領域の割合に基づく探索進捗率を定義し、レベルセット推定手法を応用した獲得関数により、適切なタイミングでの終了判定が可能なベイズ最適化を提案する。
[1-R-063] 最大値バンディット問題における UCB 方策の最適性
発表者 吉川信明 (株式会社豊田中央研究所), 大野宏司 (株式会社豊田中央研究所)
概要 通常のバンディット問題では総報酬の最大化が目指される。一方、得た報酬の最大値に注目してその最大化を目指す最大値バンディット問題も材料探索やハイパーパラメータ探索の基礎として研究されている。本研究では通常のバンディット問題と最大値バンディット問題を統一的に扱う理論を提案し、UCB 方策が最大値バンディット問題を含む多くの問題で最適腕以外を選ぶ回数が最適方策と同じオーダーになることを証明した。
[1-R-064] 深層Koopman-layeredモデル
発表者 橋本悠香 (NTT), 岩田具治 (NTT)
概要 本発表では,非斉次力学系から生じる時系列データを解析するための,深層Koopman-layeredモデルを提案する.深層Koopman-layeredモデルは,作用素論的データ解析に基づき,Toeplitz行列形式で学習パラメータを持つ,理論解析のしやすさと柔軟性の両方を備えたモデルである.Toeplitz行列の普遍近似性とモデルにおける再生性により,モデルの普遍近似性と汎化性能を示す.さらに,モデルの柔軟性により,非斉次力学系から生じる時系列データに対しても高精度に解析を行う.
[1-R-065] Box embedding を用いたテキスト情報に基づく嗜好推定手法の検討
発表者 鷲見 優一郎 (トヨタ自動車株式会社 未来創生センター), 中西 亮輔 (トヨタ自動車株式会社 未来創生センター)
概要 推薦システムにおいて、ユーザーの嗜好推定は重要な課題である。従来アイテム情報は埋め込み空間内のベクトルで表現されてきた。このベクトルを用いて嗜好を推定する手法には、アイテムが本来持つ多様性や曖昧性の表現能力に課題がある。本研究では商品説明文などのテキスト情報を入力とし、Box embeddingでそのアイテムを表現する。その表現を基に購買予測タスクを行い性能を検証する。
[1-R-066] 連続関数に対するNeural ODEのOrlicz universal approximation propertyについて
発表者 川澄 亮太 (神戸学院大学), 池田 正弘 (理研AIP)
概要 本発表では, Teshimaらによって得られたNeural ODEの近似能力で扱う関数空間の統一および一般化を試みる. 具体的には, BirnbaumとOrliczによって考えられたOrlicz空間を導入して, Orlicz universal approximation propertyについて考える. 先行研究で扱っているLebesgue空間や有界関数全体での空間とオーリッツ空間との関係性や性質について述べ, 更にOrlicz空間上でのNeural ODEの普遍性についての証明を与える. 証明のポイントは, 新しい型のグロンフォールの不等式を確立して, 上記の証明で用いた.
[1-R-067] 小標本におけるカテゴリー変数の水準間スパース性を用いたパラメータ推定
発表者 李根 (株式会社東芝), 高田正彬 (株式会社東芝), 四辻嵩直 (株式会社東芝), 藤澤洋徳 (統計数理研究所)
概要 カテゴリー変数を用いた回帰問題を考える。特定の水準が小標本である場合、該当水準に対するパラメータ推定が上手くいかないことがある。本研究では、水準間スパース性に基づいてパラメータを推定するいくつかの方法について検討する。数値実験により、各手法の推定精度を評価する。
[1-R-068] ターゲットドメインのサンプル数が少ない場合のドメイン適応
発表者 勝木 孝行 (IBM東京基礎研究所), Haoxiang Qiu (IBM東京基礎研究所), 坂井 智哉 (IBM東京基礎研究所), 恐神 貴行 (IBM東京基礎研究所), 井上 忠宣 (IBM東京基礎研究所), 木村 大毅 (IBM東京基礎研究所), A. Cristiano I. Malossi (IBM Research Zurich)
概要 本発表では、少数のラベルなしデータしか得られないドメインに対して、予測モデルを迅速に導入する問題を扱う。これを、ターゲットドメインのサンプル数がソースドメインのサンプル数に比べて少ない場合の教師なしドメイン適応として定式化する。サンプル数を明示的に考慮するロスを提案し、性能改善が行えることを示す。
[1-R-069] PGExplainerとグラフマイニングの融合によるスケーラブルかつ解釈可能な予測モデル構築
発表者 杉原蓮 (名古屋工業大学), 小島大河 (名古屋工業大学), 烏山昌幸 (名古屋工業大学)
概要 本研究ではGNNの説明手法であるPGExplainerとグラフマイニングを融合した予測モデルを構築する.これは予測に寄与する部分グラフ構造を厳密に発見できるという意味で解釈性の高いモデルとなっている.提案法はPGExplainerが着目した領域に絞って枝刈り付き部分グラフ列挙を行う.これによりグラフ全体からの列挙に基づく従来法と比べスケーラビリティを改善しつつ,高い予測精度が達成できることも示す.
[1-R-070] 強化学習のための物体中心表現を用いた世界モデル
発表者 西本遥裕 (大阪大学), 松原崇 (北海道大学)
概要 世界モデルは,深層強化学習の学習効率を向上させてきた.しかし,高次元で複数物体やその相互作用を含む環境において,世界モデルを効果的に学習することは困難である.私たちは,世界モデル,方策,価値関数すべてに物体中心表現を用いたTransformerを用いた強化学習手法を提案する.Safety Gymベンチマークにおいて,提案手法は従来のTransformerベースの世界モデル手法の性能を上回った.
[1-R-071] 対照学習の推定性能に関する理論解析
発表者 和井田博貴 (東京科学大学), 金森敬文 (東京科学大学/理研AIP)
概要 対照学習では通常,損失関数とベクトル値表現関数により定義される自己教師あり学習問題を解くことで下流タスクに有用な表現関数を得る.本発表では,対照学習の最小化問題における最適表現関数の獲得の観点に着目し経験リスク最小解のもつ関数推定性能を直接的に理論解析した結果を報告する.特に,対照学習を通じてデータ間の類似度に基づき区別されるノンパラメトリックな部分集合を統計的に学習できることを示す.
[1-R-072] 乱択期待改善量によるベイズ最適化
発表者 竹野思温 (名古屋大学, 理化学研究所), 稲津佑 (名古屋工業大学), 烏山昌幸 (名古屋工業大学), 竹内一郎 (名古屋大学, 理化学研究所)
概要 ベイズ最適化において期待改善量は経験的に良い性能を持つ. 一方で, その理論解析は未だほとんどない. また, 観測にノイズが含まれる場合, ノイズの影響を調節するハイパーパラメータを手動でチューニングする必要がある. 本研究では, 事後分布のサンプルからの改善量を用いることで, チューニング不要かつ理論保証のある乱択期待改善量を提案する.
[1-R-073] Neural combinatorial optimization for inventory routing problem
発表者 牧野 舜 (株式会社フレクト)
概要 In recent years, Neural Combinatorial Optimization (NCO), which is the research area on applying Reinforcement Learning (RL) to solve combinatorial optimization problems, such as vehicle routing problem has been studied. Heuristics is a typical traditional method, but it hardly depends on extensive expertise. NCO could overcome the limitation by leveraging RL’s ability to learn in the absence of optimal solutions. In this presentation, we will discuss its application to a simplified inventory routing problem.
[1-R-074] Differentially Private Best-Arm Identification
発表者 Achraf Azize (Inria), Marc Jourdan (Inria), Aymen Al Marjani (Amazon), Debabrota Basu (Inria)
概要 Best Arm Identification (BAI) problems are progressively used for data-sensitive applications, such as designing adaptive clinical trials, tuning hyper-parameters, and conducting user studies to name a few. Motivated by the data privacy concerns invoked by these applications, we study the problem of BAI with fixed confidence under ϵ-global Differential Privacy (DP). First, to quantify the cost of privacy, we derive a lower bound on the sample complexity of any δ-correct BAI algorithm satisfying ϵ-global DP. Our lower bound suggests the existence of two privacy regimes depending on the privacy budget ϵ. In the high-privacy regime (small ϵ), the hardness depends on a coupled effect of privacy and a novel information- theoretic quantity, called the Total Variation Characteristic Time. In the low-privacy regime (large ϵ), the sample complexity lower bound reduces to the classical non- private lower bound. Second, we propose AdaP-TT, an ϵ-global DP variant of the Top Two algorithm. AdaP-TT runs in arm-dependent adaptive episodes and adds Laplace noise to ensure a good privacy-utility trade-off. We derive an asymptotic upper bound on the sample complexity of AdaP-TT that matches with the lower bound up to multiplicative constants in the high-privacy regime. Finally, we provide an experimental analysis of AdaP-TT that validates our theoretical results.
[1-R-075] メタ学習された観測に動的なMulti-fidelityガウス過程によるMulti-fidelityベイズ最適化
発表者 伊藤由騎 (名古屋工業大学), 烏山昌幸 (名古屋工業大学)
概要 Multi-fidelityベイズ最適化は最適化対象の近似関数を低コストで観測できる場合のベイズ最適化手法である.しかし,一般に近似関数と最適化対象の関係性は事前には未知であり,最適化しながらこの関係性を推定するのは容易ではない.本研究では,ディープカーネルに現状の観測データを渡すことでfidelity間の関係性が動的に変化するガウス過程を事前データによりメタ学習する枠組みを提案する.
[1-R-076] 相互情報量に対する変分下限最大化に基づく多目的ベイズ最適化
発表者 石倉雅紀 (名古屋工業大学), 烏山昌幸 (名古屋工業大学)
概要 多目的ベイズ最適化の獲得関数としてパレートフロンティア(PF)に関する情報量の変分下限最大化を提案する.本来,情報量の評価にはPF全体が必要となるが,多くの場合,実際にはPFを構成する一部の点しか得られない.本研究では,悲観的及び楽観的な二種類の近似PFから成る分布を考え,それらを混合した変分分布の混合比を変分下限最大化で最適化することで,活用と探索のバランスが適応的に定まる獲得関数を設計する.
[1-R-077] 有向グラフでの複素Non-backtracking行列とクラスタリングへの応用
発表者 三戸圭史 (総合研究大学院大学), 日野英逸 (統計数理研究所/理研AIP)
概要 有向グラフの行列表現の1つであるエルミート隣接行列に対応するNon-backtracking(NBT)行列として,複素NBT(CNBT)行列を提案する.無向グラフの隣接行列とNBT行列間で成立するいくつかの関係がエルミート隣接行列とCNBT行列間でも成り立つことを示し,また数値実験によって,スパースグラフのノードクラスタリングでは提案手法が既存手法よりも頑健な推定が可能であることを示す.
[1-R-078] 深層学習による画像ベースのダイナミクス同定と最適制御
発表者 吉岡朋哉 (大阪大学), 松原崇 (北海道大学)
概要 複雑な環境下でロボットを制御する際,位置や速度などの状態が直接観測できるとは限らないため,画像に基づいて制御できることが望ましい.しかし,画像から状態を正確に観測することは困難であり,ロボットが従う方程式が未知である場合,制御入力は得られない.本研究では,深層学習を用いて画像から状態を抽出し,それを基にモデル化を行うことで,多関節ロボットアームの画像ベースの制御が可能であることを示した.
[1-R-079] 訓練損失の大域解集合上における汎化誤差の理論的解析
発表者 吉田直生 (東京大学), 今泉允聡 (東京大学/理研AIP)
概要 本研究では,機械学習モデルの大域解集合上における汎化誤差を理論的に解析した.従来の統計理論を用いて導出された汎化誤差の上界値は,一般にモデルのパラメータ数が増えるほど大きくなるが,この理論的事実は深層学習などのパラメータ数の多いモデルがよく汎化するという経験的事実に矛盾している.本研究は,実際の深層学習はゼロ損失を達成するなど特徴的な大域解に至る事実に注目し,訓練損失の大域解集合に限定して汎化誤差解析を行う.具体的には,Hausdorff次元・Hausdorff測度という概念を利用することで,機械学習モデルの訓練損失の大域解集合の実質的な次元を測り,パラメータ数に明示的に依存しない汎化誤差バウンドを導出する.
[1-R-080] 深層学習による連成系のモデル化と相互作用の学習
発表者 コスロービアンラズミックアルマン (大阪大学), 谷口隆晴 (神戸大学), 吉村浩明 (早稲田大学), 松原崇 (北海道大学)
概要 方程式が未知の動的システムを深層学習を用いてデータからモデル化することは,シミュレータや制御器の自動構築やシステムの理解に重要である.しかし,既存手法は機械系にしか適用できず,システムを一体的に扱うため連成系をそのままモデル化できない.そこでディラック構造を用い,機械系や電気回路など複数の領域にまたがるシステムや各要素の相互作用と制約を統一的に表現できる深層学習モデルを提案する.
[1-R-081] 局所解析汎函数上の押し出しの有限次元近似について
発表者 石川勲 (愛媛大学)
概要 力学系から定まる局所解析汎函数上の押し出し写像の有限次元近似をデータ駆動的行う理論的な枠組みについて紹介する。この枠組みによって力学系のデータ駆動解析において重要な動的モード分解を組織的に取り扱うことが可能となり、DMDのアルゴリズムによって得られる近似行列について数学的に厳密な解釈を与えることが可能となる。応用として、ユークリッド空間上の解析的なベクトル場について、ベクトル場から定まる力学系の軌道上の離散的なデータから元のベクトル場を復元する手法についても紹介する。
[1-R-082] 量子回路C*-algebra netのためのエンタングルメント損失の検討
発表者 幡谷龍一郎 (理研AIP), 橋本悠香 (NTT,理研AIP)
概要 C*-algebra netの特殊例である量子回路C*-algebra netは,互いに情報共有を行う複数の量子機械学習モデルを表現していると見なせる. 本発表では,情報共有の強度をエンタングルメントを損失に取り入れて制御することを検討する.
[1-R-083] 引力と斥力を制御可能なべき集合上の分布族
発表者 川島貴大 (ZOZO Research), 日野英逸 (統数研, 理研AIP)
概要 ランダムな部分集合を支配する確率分布では,Positive/Negative Dependenceとよばれる一種の引力・斥力がその振る舞いを本質的に特徴づける.ランダム部分集合は広範な分野で現れる概念である一方,引力・斥力が制御可能かつ工学的実用性も備えた確率モデルの選択肢は非常に限られている.そこで本発表ではランダム部分集合のための新たな分布族を提案し,その基本的な扱いや表現力について議論する.
[1-R-084] リザバーコンピューティングによる競技かるたの決まり字の解析
発表者 松田 孟留 (東京大学, 理研CBS), 朝吹 俊丈 (理研CBS), 谷本 彩 (理研CBS)
概要 競技かるたとは、百人一首の札を取る速さを競うスポーツである。どの札が読まれたか一意に定まる最初の数文字のことを決まり字とよぶ。たとえば、「ち」で始まる札は3枚あり、決まり字はそれぞれ「ちは」「ちぎりき」「ちぎりお」である。本研究では、リカレントニューラルネットワークを用いたリザバーコンピューティングによって読み音声データを解析し、決まり字より早い段階で札を識別できるか検証する。
[1-R-085] The Age of Superintelligence: ~Capitalism to Broken Communism~
発表者 石崎龍之介 (NII), 杉山麿人 (NII)
概要 In this study, we metaphysically discuss how societal values will change and what will happen to the world when superintelligence is safely realized. By providing a mathematical definition of superintelligence, we examine the phenomena derived from this thesis. If an intelligence explosion is triggered under safe management through advanced AI technologies such as large language models (LLMs), it is thought that a modern form of broken communism—where rights are bifurcated from the capitalist system—will first emerge. In that era, the value of humans will ultimately eliminate external factors, and beings without superintelligence will converge into irreplaceable existences possessing only intrinsic value. The world will be divided into those who possess superintelligence and those who do not. For better or worse, global standardization will progress, and due to over-simulation accompanying the intelligence explosion, we may become unable to distinguish whether the reality we inhabit is original or a copy created through augmented reality. Note: In the creation of this paper, we have undertaken all writing ourselves and have not used generative AI for text generation except for translation purposes.
[1-R-086] 自己蒸留におけるソフトラベルの役割
発表者 高波海斗 (東大理), 髙橋昂 (東大理), 坂田綾香 (統計数理研究所)
概要 知識蒸留は、大規模モデルの知識を小規模モデルに転移する手法である。自己蒸留では、同じモデルを教師と生徒に用いることで、生徒が教師を上回る汎化性能を示すことが知られている。これは、教師の出力が生のデータ以上の情報を持つことを示唆するが、その具体的な仕組みは未解明である。そこで本研究では、単層ニューラルネットワークを用いた分類タスクを解析し、自己蒸留における教師のラベルが果たす役割を考察した。
[1-R-087] モデル性能を保証した分布ロバストな訓練事例選択
発表者 田中智成 (名古屋大学), 花田博幸 (理化学研究所), Hanting Yang (名古屋大学), 青山竜也 (名古屋大学), 稲津佑 (名古屋工業大学), 赤羽智志 (名古屋大学), 大藏芳斗 (名古屋大学), 橋本典明 (理化学研究所), 村山太朗 (株式会社デンソー), 李翰柱 (株式会社デンソー), 小嶋信矢 (株式会社デンソー), 竹内一郎 (名古屋大学/理化学研究所)
概要 既存の訓練データ集合から小規模な部分集合を選び出すデータ選択手法はコアセット選択と呼ばれ,様々な手法が提案されている.本研究では,開発段階と運用段階でデータ分布が異なり,かつ,後者が未知である場合のコアセット選択問題を考察し,新方法を提案する.提案法は,データ分布の変動範囲を指定した場合において,モデル性能低下を抑えつつ理論的なモデル性能保証を提供した上で,不要な訓練データを特定することができる.
[1-R-088] 時空間グラフ深層学習における過平滑化現象
発表者 水口智也 (京都大学大学院総合生存学館)
概要 近年、時空間データの特性を効果的に捉えられる手法として、時空間グラフ深層学習(STGNN)が注目を集めており、交通流、天候、感染症の蔓延等、幅広い分野で高精度の予測に役立てられている。STGNNでは、様々なモデルの開発が進められているが、説明性、理論等、モデル自体への理解が不足している。そこで本研究は、STGNNにおける過平滑化現象について検証を行い、内部挙動に関する知見を提供するとともに、検証結果からSTGNN内のメッセージ伝達を改良した、新たな手法を提案する。
[1-R-089] 制約求解を用いない検証ベースの公平性テスト技術
発表者 Zhao Zhenjiang (気通信大学/産業技術総合研究所), 戸田貴久 (気通信大学), 北村崇師 (産業技術総合研究所)
概要 機械学習モデルの公平性テストは、与えられたモデルにおける公平性の違反を検出する。検証ベース手法は、一連の公平性テスト技術である。従来の研究では、検証ベース手法でテストケースを生成する際に制約求解を用いてきたが、制約求解はNP困難であり、効率の課題がある。本発表では、制約求解を使用せずにパスサンプリングを採用することで、検証ベース手法のテストケース生成部分を改良する新たな手法を紹介する
[1-R-090] Comparative Analysis of Domain-Specific and Geometric Deep Learning Models in Chemical Property Predictions
発表者 Chenghan Sun (ICReDD, Hokkaido University), Zekun Chen (University of California, Davis), Wang-Yeuk Kong (University of California, Davis), Ichigaku Takigawa (ICReDD, Hokkaido University, Kyoto University)
概要 This study aims to perform a comprehensive benchmarking comparison of two machine learning (ML) approaches—domain-specific models and end-to-end models—for predicting node-level atomic properties in quantum chemistry. The increasing complexity of subjects and targets in natural sciences has recently spurred growing interest in AI for Science (AI4S). Consequently, two parallel research approaches have emerged: domain-specific models, which integrate traditional machine learning algorithms with methods (typically descriptors or “fingerprints”) tailored for specific purposes, and graph-based models, which emphasize end-to-end ML with minimal incorporation of domain knowledge. Despite the prominence of these approaches, detailed technical comparisons between them are still lacking. In this case study, we systematically investigate (1) a domain-specific deep learning (DL) model based on chemical descriptors and (2) end-to-end models leveraging state-of-the-art geometric deep learning (GDL) using Graph Neural Networks (GNNs) and large pre-trained models for predicting atomic properties. The study uses a unique dataset provided by our international collaborators at the University of California, Davis.
[1-R-091] 制約付き選好ベイズ最適化によるクリック率を考慮したバナー広告デザイン
発表者 岩井皓暉 (株式会社博報堂DYホールディングス), 熊谷雄介 (株式会社博報堂DYホールディングス), 小山裕己 (産業技術総合研究所), 濱崎雅弘 (産業技術総合研究所), 後藤真孝 (産業技術総合研究所)
概要 バナー広告をデザインする際には,クリック率と見た目の好ましさの両方を考慮することが求められる.本発表では,システムがクリック率を考慮しながらデザイナが好ましいデザインの探索を進めるデザイナ支援フレームワークと,それを技術的に実現するための制約付き選好ベイズ最適化手法を提案する.我々は,バナー広告の色やレイアウトを編集するためのプロトタイプシステムを開発し,ユーザスタディを実施した.
[1-R-092] MLP-Mixer の大次元かつ疎な MLP としての理解
発表者 早瀬友裕 (クラスターメタバース研究所), 唐木田亮 (AIST)
概要 MLPは深層学習における重要な構成要素である. しかし, MLP-MixerはMLPにさらなる改良の余地があることを示唆している. 本研究では, MLP-Mixerが疎な重みを持つワイドなMLPとして表現され, 機能することを示す. この表現はクロネッカー積と置換行列による. その結果, MLP-MixerのMLPとしての隠れ層次元が極めて大きいことが, その高い性能の原因と明らかになった.
[1-R-093] AlphaFold2のAttentionメカニズムの解析
発表者 野崎幸成 (名古屋大学 応用物理学専攻), Chavas Leonard (名古屋大学 応用物理学専攻, シンクロトロン光センター), 千見寺 浄慈 (名古屋大学 応用物理学専攻)
概要 本研究では、AlphaFold2のAttentionメカニズムがどのようなパターンを形成しているかを解析しました。Attention重みの分布を詳しく調査した結果、特定のパターンが予測結果に影響を与えていることが示唆され、これがタンパク質構造予測の精度向上に寄与している可能性が示されました。本研究は、機械学習ベースのタンパク質構造予測モデルにおいて、Attentionメカニズムがどのように機能しているかを理解することで、予測性能の向上に向けた新たな視点を提供することを目的としています。
[1-R-094] Long-term Time Series Forecasting via Time-Frequency Dual-domain Learning
発表者 白晶晶 (大阪大学), 河原吉伸 (大阪大学・RIKEN)
概要 本研究では、時系列予測のための精度と解釈可能性の向上を同時に実現するため、時間/周波数の両ドメインの特徴を融合的に用いたトランスフォーマーモデルを提案する。既存手法の高い計算コストや表現力不足などの課題に対し、本研究では、周波数解析に基づきデータの長期的依存関係を適応的に捉え、季節変動や周期性などの大域的特徴を用いることで、高次元時系列データにおける長期的な予測を高い性能で実現する。
[1-R-095] 文脈内学習設定における言語モデルの出力較正
発表者 鴨田豪 (東北大), 伊藤郁海 (東北大学), 熊谷雄介 (株式会社博報堂DYホールディングス), 横井祥 (東北大学・理化学研究所)
概要 文脈内学習は、簡単な指示や少数事例を与えることで言語モデルを幅広いタスクに適応させるための手法である。パラメータ更新が不要で手軽なこの文脈内学習を利用して分類問題を解く際、予測分布の偏りが負の影響を与えることがある。我々は、文脈内学習が少数事例を逐次的に与える設定であることに着目して、モデルによる推論の定式化と較正手法の検討を行う。
[1-R-096] Identification of the Strongest Die in Dueling Bandits
発表者 Shang LU (Department of Informatics, Kyushu University), Kohei HATANO (RIKEN AIP), Shuji KIJIMA (Faculty of Data Science, Shiga University), Eiji TAKIMOTO (Department of Informatics, Kyushu University)
概要 This work introduces the ¥emph{dueling dice problem}, which is a variant of the multi-armed dueling bandit problem. A ¥emph{die} is a set of $m$ arms in this problem, and the goal is to find the best set of $m$ arms from $n$ arms ($m ¥leq n$) by an iteration of dueling dice. In a round, the learner arbitrarily chooses two dice $¥alpha ¥subseteq [n]$ and $¥beta ¥subseteq [n]$ and lets them duel, where she roles dice $¥alpha$ and $¥beta$, observes a pair of arms $i ¥in ¥alpha$ and $j ¥in ¥beta$, and receives a probabilistic result $X_{i,j} ¥in ¥{0,1¥}$. This paper investigates the sample complexity of an identification of the Condorcet winner die, and gives an upper bound ${¥rm O}(nh^{-2}(¥log{¥log{h^{-1}}}+¥log{nm^2¥gamma^{-1}})m¥log{m})$ where $h$ is a gap parameter and $¥gamma$ is an error parameter. Our problem is closely related to the dueling teams problem by Cohen et al.¥ 2021. We assume a total order of the strength over arms similarly to Cohen et al.¥ 2021, which ensures the existence of the Condorcet winner die, but we ¥emph{do not} assume a total order of the strength over dice unlike Cohen et al.¥ 2021.
[1-R-097] 二層ニューラルネットワークの学習ダイナミクスと大域最適解の到達可能性
発表者 西山颯大 (東京大学), 市川佑馬 (東京大学,富士通), 福島孝治 (東京大学), 今泉允聡 (東京大学,理研AIP)
概要 ニューラルネットワークの勾配降下法による学習は,ロスの非凸性により最適解への到達可能性は保証されていない.一方で,経験的には勾配降下法がしばしば最適解に到達することが知られている.本研究では,ランダムなデータを分類する2層ニューラルネットワークの勾配降下法による学習ダイナミクスを理論的に解析し,その性質と最適解への到達可能性を探る.
[1-R-098] 幅無限大極限における局所学習則:Predictive CodingおよびTarget Propagationのための安定なパラメータ化について
発表者 石川智貴 (東京科学大学), 横田理央 (東京科学大学), 唐木田亮 (産業技術総合研究所)
概要 Local learning, which trains a network through layer-wise local targets and losses, has been studied as an alternative principle to backpropagation (BP) in neural computation. However, its algorithms often become more complicated or require additional hyperparameters due to the locality, making it challenging to identify desirable settings where the algorithm progresses in a stable manner. To gain theoretical and quantitative insight, we introduce a maximal update parameterization (muP) in the infinite-width limit for two representative designs of local targets: predictive coding (PC) and target propagation (TP). We verify that muP enables hyperparameter transfer across models of different widths. Furthermore, our analysis of parameterization presents unique and intriguing properties not observed in conventional BP. Leveraged by the analysis of deep linear networks, we find that PC’s gradients interpolate between BP and Gauss-Newton-like gradients, depending on the parameterization. We demonstrate that, in some common settings, PC in the infinite-width limit leads to behavior more similar to BP. For TP, even with the standard scale of the last layer different classical muP, it prefers feature learning rather than the kernel regime.
[1-R-099] 所定の結晶構造と物性を達成できる勾配ベースの逆問題解法によるマテリアルデザイン手法
発表者 藤井亮宏 (東京大学マテリアル工学科), 牛久祥孝 (オムロンサイニックエックス), 清水康司 (産業技術総合研究所), Anh Khoa Augustin Lu (東京大学マテリアル工学科), 渡邉聡 (東京大学マテリアル工学科)
概要 材料科学では目的の特性を持つ結晶構造の探索が重要である。しかし、既存の手法では電気的中性や特定の結晶構造の維持など様々な制約を適応的に組み込むのが困難であった。これを解決するために我々はSMOACSを開発した。SMOACSは最先端の特性予測モデルとその勾配を利用しモデルの再学習なしで制約を組み込んだ最適化を可能する。これにより、ペロブスカイト構造を維持しつつ、電気的中性を保ったままバンドギャップの最適化を実現した
[1-R-100] 確率的勾配降下法の平滑化効果を利用した段階的最適化アルゴリズムによる経験損失最小化問題のための大域的最適化
発表者 佐藤尚樹 (明治大学), 飯塚秀明 (明治大学)
概要 本発表は,確率的勾配降下法が抱えている確率的なノイズに着目し,このノイズが目的関数を平滑化していること,その度合いが学習率とバッチサイズによって定まることを示す.そして,その性質を利用した暗黙的な段階的最適化アルゴリズムを構築し,深層学習モデルの大域的最適化が可能であることを示す.また,確率的ノイズによる平滑化の度合いとモデルの汎化性能の間には相関があることを示す.
[1-R-101] 非負性・万能近似性・線形性を同時に満たすカーネルモデルに関する考察
発表者 金秀明 (NTT)
概要 正定値カーネルの線形和で表現された関数近似器(カーネルモデル)は,適切なカーネルの下で万能近似性を有することで知られる.しかし,その出力に非負制約を課す場合,カーネルモデルは万能近似性を担保できないと考えられてきた.本研究では,M-行列と呼ばれる行列要素の符号に関する理論を導入し,カーネルモデルが非負性と万能近似性を両立するための十分条件を示す.さらに,その条件を満たす具体的なモデルを例示する.
[1-R-102] Koopman作用素を用いた深層ニューラルネットワークのモデル圧縮
発表者 相島 祐太 (NAIST), 池田 和司 (NAIST)
概要 エッジAIの普及に伴い、深層ニューラルネットワークのモデル圧縮の需要は高まっている。本研究では多層パーセプトロンに注目し、Koopman作用素を応用した多層パーセプトロンの深さ削減によるモデル圧縮を提案する。本発表では、提案手法の理論的背景と人工データによる関数近似タスクの結果を示す。
[1-R-103] 多層ニューラルネットワークを弱学習器として用いたBoosting手法の検討
発表者 斉藤優也 (九大), 松尾信之介 (九大), 内田誠一 (九大), 末廣大貴 (九大, 理研AIP)
概要 Boostingは弱学習器と呼ばれる性能が低い学習器を統合し,強力な学習器を構築する方法である.多層ニューラルネットワーク(NN)は,多くの場合訓練データを十分に学習できる強力な学習器であり,Boostingとの相性は良くない.そこで,学習性能を意図的に弱めた多層NNを弱学習器として利用する方法を検討する.様々なパラメータ及びデータを用いた実験的評価を行い,理論および実用上の課題について議論する.
[1-R-104] 正規化最尤符号に基づく直接原因変数の学習
発表者 久保木優太 (東京大学), 小林将理 (東京大学), 松島慎 (東京大学)
概要 本研究では、ターゲット変数の直接原因変数を推定する局所的因果探索の問題を考える。 これは介入施策の策定にとって重要であり、全体の因果構造を推定する大域的探索に比べて、比較的緩やかな仮定の元で効率的に学習できる。 既存手法では仮説検定を用いるために様々な問題が生じるが、我々は、一致性のあるNML符号を用いる2変数間の因果探索手法を拡張し、MDL原理に基づくモデル選択の枠組みでこの問題に取り組む。
[1-R-105] 推定された密度比を用いる重要度重み付け共変量シフト適応の再考
発表者 加藤真大 (みずほ第一フィナンシャルテクノロジー), 松井孝太 (名古屋大), 井口亮 (みずほ第一フィナンシャルテクノロジー)
概要 本研究では,共変量シフト下で予測モデルの学習において,密度比を用いる重要度重み付けによりテストデータにおける経験リスクを近似するアプローチを考える.密度比が未知の場合,その推定量で置き換えることが一般的であるが,その操作は経験リスクにバイアスが生じさせる可能性がある.我々はこの問題に対して,予測モデルが達成しうる望ましい性能値に対して,密度比の推定誤差を無視できるようにする手法を提案する.
[1-R-106] 動的商品カタログを持つECサイトのための寿命型バンディットアルゴリズム
発表者 菊池健太 (北海道大学), 田畑公次 (北海道大学), 小松崎民樹 (北海道大学)
概要 本研究では、動的に変化する商品カタログを持つECサイトにおける商品推薦アルゴリズムの開発を目的とする。特に、各商品が寿命を持ち、埋め込みベクトルで表現される状況を考慮し、これらの商品によって構成される腕の集合が動的に変化する環境下での多腕バンディットアルゴリズムを提案する。提案手法の有効性は、シミュレーションを通じて検証を行う。
[1-R-107] Neural Architecture Searchにおけるアーキテクチャの特徴量空間の分析と活用
発表者 逸見一喜 (筑波大, 産総研), 谷垣勇輝 (大阪工業大), 大西正輝 (産総研)
概要 Neural Architecture Searchのアーキテクチャ特徴量の抽出にはGraph Neural Networkの手法がよく用いられるが,埋め込み後の潜在空間の詳細は未だ不明である.本研究では,NAVIGATORとNASBenchを用いて複数構造の潜在特徴量空間を獲得し,埋め込み前後の入出力関係を分析する.また,ユーザが望む潜在空間への変換方法についても検討する.
[1-R-108] アンダーバギング法の比例的漸近論
発表者 髙橋昂 (東京大学大学院 理学系研究科附属 知の物理学研究センター)
概要 データ数とパラメータの次元が比例して大きくなる漸近領域において、モデルの推定結果を精密に評価する手法が近年発展している。本研究では、不均衡データに対してアンダーサンプリングとバギングを組み合わせたアンダーバギング法の振る舞いを、比例的漸近領域で定量的に解析した。この表式をもとに、アンダーバギング法の特徴を明らかにし、他の不均衡データへの対処法と比較した結果を紹介する。
[1-R-109] GFlowNets による多様性制御生成モデルの学習
発表者 三森隆広 (早稲田大学), 浜田道昭 (早稲田大/産総研-早大CBBD-OIL/日本医科大学)
概要 GFlowNets は DNA/RNA 配列や化合物などの離散変数を有向グラフ上のフローに従って生成するモデルであり,末端ノードへのフローを非負の報酬に近づける学習を行う.生成変数の報酬と多様性のバランスは報酬の指数によって制御可能であるが,ハイパーパラメータとして扱うことが多い.本研究では GFlowNets と分布強化学習の関係を議論し,生成時に多様性を制御可能なモデルの学習方法を提案する.
[1-R-110] バンディットアルゴリズムを用いた高次元ベイズ最適化の効率化の検討
発表者 野村祐介 (北海道大学電子科学研究所), 田畑公次 (北海道大学電子科学研究所), 小松崎民樹 (北海道大学電子科学研究所)
概要 高次元空間におけるベイズ最適化は、ガウス過程回帰による推定が不安定になるなどのことから通常のベイズ最適化のパフォーマンスが低下する。この課題に対し、一つのアプローチとして次元選択を行う手法が提案されてきた。本研究では、この次元選択プロセスにバンディットアルゴリズムを導入することで、より効率的な高次元ベイズ最適化手法を提案する。提案手法の有効性を従来手法との比較実験により検証する。
[1-R-111] バンディットフィードバック下でのクラスタリング問題
発表者 瀧川颯士 (北海道大学電子科学研究所), 田畑公次 (北海道大学電子科学研究所), 小松崎民樹 (北海道大学電子科学研究所)
概要 本研究では、バンディットフィードバックを用いたクラスタリング問題に取り組む。特にクラスタ数が未知の場合におけるクラスタリング手法を扱う。クラスタ数が既知である場合には従来研究があるが、実際の応用では未知であることが多い。そこで、本研究では、固定信頼度設定の多腕バンディット問題の枠組みを活用し、クラスタ数と割り当てを同時に最適化する手法を提案する。さらに、停止時間により提案手法の有効性の評価を行う。
エントリー
[1-E-01] 紫外線宇宙望遠鏡の観測した地球放射線帯由来のイメージに対する異常検知の適応
発表者 古賀亮一 (名市大), 小山聡 (名市大), 能勢正仁 (名市大), 吉岡和夫 (東大)
概要 過去10年間、機械学習を用いた異常検知に関する研究は検出精度を高める方向性のものが多かった。しかし、科学的理解のためには、なぜそのような予測がなされたのかを解釈できることも重要である。本研究では異常検知の技術を放射線から来た高エネルギー粒子が宇宙望遠鏡のMCP検出器に届くことによって撮像されたスペクトルイメージに適応し、最終的には地球放射線帯のダイナミクスの理解につなげることを目指す。
[1-E-02] ストリーミング情報に基づく走行環境の複雑性を考慮したオンライン経路制御:実験環境構築と検証
発表者 倉見 明日花 (早稲田大学), 和佐 泰明 (早稲田大学), 岸田 昌子 (国立情報学研究所)
概要 本発表では,カメラを搭載した自律移動型ロボットのオンライン経路制御手法を提案する.まず,天井から映写された路面と実空間での障害物を配置した拡張現実実験環境を整備し,カメラ画像から機械学習技術を用いて環境情報の深度推定と画像識別が行えることを示す.次に,得られた情報から評価した走行環境の複雑性を制御バリア関数に組み込み,安全走行可能な制御手法を提案する.最後に提案手法の有効性を実験検証する.
[1-E-03] PU学習の枠組みにおけるエンタングルメント検出の定式化
発表者 野原 大靖 (北海道大学), 野田 五十樹 (北海道大学), 小山 聡 (名古屋市立大学)
概要 いくつかの制約を満たす複素行列として表現される量子状態は、エンタングルしている状態とそうでない状態に大別される。近年、機械学習を用いたエンタングルな状態の検出方法が研究されているが学習データとしてエンタングルな状態のラベルを付与するコストについて着目した研究は少ない。本発表においてはPU学習の枠組みを用いてコストの低い「ラベルなし」量子状態を用いたエンタングルメント検出の定式化を行う。
[1-E-04] 多目的分類バンディット
発表者 鈴木理矩 (北海道大学大学院情報科学院), 中村篤祥 (北海道大学大学院情報科学研究院)
概要 K本のアームの内、閾値以上の期待報酬をもつ腕がL(≦K)本以上存在するか否かを、1-δ以上の確率で正しく判定する多目的分類バンディット問題を提案する。サンプル数の漸近的下界から導かれる各アームを引く割合の最適値と最適停止条件を導出し、単目的のP-Trackingを多目的版に拡張した。人工データを用いた実験では、他の既存手法の多目的拡張版よりも平均的に少ないサンプル数で、全て正しい判定を出力した。
[1-E-05] 線形関数近似器を用いたTD学習によるマルチエージェント強化学習における学習曲線予測
発表者 仲野凌平 (茨城大), 木村俊 (群馬大), 竹田晃人 (茨城大)
概要 MARL(Multi Agent Reinforcement Learning: マルチエージェント強化学習)とは行動の主 体であるエージェントが学習環境内に複数個存在し,互いに協調ないしは競争しながらシ ステム全体を最適化する行動指針の獲得を目指す強化学習手法である. 本研究では,線形関数近似器を学習器としたシングルエージェントによる強化学習にて学習曲線(ここではTD誤差の推移)を理論的に可視化した先行研究をもとに,MARLでも学習曲線の予測を試みる.
[1-E-06] 自動ポートフォリオ最適化のための移動平均回帰を活用したリスク分散戦略
発表者 林佑宜 (北海道大学情報科学院), 中村篤祥 (北海道大学情報科学院)
概要 自動ポートフォリオ最適化はアルゴリズムやモデルを通じて投資ポートフォリオの資産配分を自動的に最適化する方法である。 経験則によれば、株価は平均回帰理論に従う可能性が高い。 既存の平均回帰戦略は、多くの実世界のデータセットにおいてベンチマークを超える結果を達成するが、それらは単一銘柄のポートフォリオを構築する傾向があり、高いリスクをもたらす。そこで平均回帰戦略のリスク分散版を提案する。
[1-E-07] 決定木ベースモデルへのロバスト性の検証技術を利用したブラックボックス手法の検討
発表者 久保 拓巳 (電気通信大学 情報理工学研究科 情報ネットワーク工学専攻), 戸田 貴久 (電気通信大学情報理工学研究科 情報ネットワーク工学専攻)
概要 機械学習モデルは安全性が要求される分野で多く利用されるようになっており.あるモデルの摂動に対する強さ(ロバスト性)を評価することは重要な課題となっている.決定木モデルのロバスト性の検証について,最大クリーク問題への帰着と近似アルゴリズムを用いて効率的に行う手法が報告されている.本研究では,この手法をブラックボックスモデルでのロバスト性の検証へ応用するアイデアについて検討する.
[1-E-08] Uncertainty-penalized Bayesian information criterion for parametric partial differential equation discovery
発表者 Pongpisit Thanasutives (Osaka University), Ken-ichi Fukui (Osaka University)
概要 Data-driven discovery of partial differential equations (PDEs) has emerged as a promising approach for deriving governing physics when domain knowledge about observed data is limited. Despite recent progress, the identification of governing equations and their parametric dependencies using conventional information criteria remains challenging in noisy situations, as the criteria tend to select overly complex PDEs. In this paper, we introduce an extension of the uncertainty-penalized Bayesian information criterion (UBIC), which is adapted to solve parametric PDE discovery problems efficiently with low computational resources. This extended UBIC uses quantified PDE uncertainty over different temporal or spatial points to prevent overfitting in model selection. The UBIC is computed with data transformation based on power spectral densities to discover the governing parametric PDE that truly captures qualitative features in frequency space with a few significant terms and their parametric dependencies (i.e., the varying PDE coefficients), evaluated with confidence intervals. Numerical experiments on canonical PDEs demonstrate that our extended UBIC can identify the true number of terms and their varying coefficients accurately, even in the presence of noise.
[1-E-09] Deciphering Latent Cyclic Dynamics through Auxiliary Variable Selection in CEBRA
発表者 Fuka Uenaka (Kyoto Women’s University, Nara Institute of Science and Technology), Suzuka Higashitsutsumi (Kyoto Women’s University, Nara Institute of Science and Technology), Yuki Maruno (Nara Institute of Science and Technology), Takatomi Kubo (Nara Institute of Science and Technology)
概要 CEBRA (Consistent EmBeddings of high-dimensional Recordings using Auxiliary variables) was proposed as an extension of non-linear independent component analysis, aiming to generate consistent embeddings from high-dimensional inputs through contrastive learning based on auxiliary variables. In the original work, Schneider et al. demonstrated CEBRA’s strong performance in reconstructing latent structures and provided a theoretical guarantee for linear identifiability. In their numerical experiments, they used artificially generated 100-dimensional inputs from a 2-dimensional S-shaped latent structure, with the phase of the S-shape serving as the auxiliary variable. However, a potential issue arises when applying CEBRA to data with latent structures shaped by complex cyclic dynamics, particularly due to the inherent limitations of contrastive learning. This issue persists even when auxiliary variables related to such cyclic dynamics are available. When temporal information is used as the auxiliary variable, different time points with the same phase cannot be treated as positive instances. Conversely, if the values of a cyclic function are used as the auxiliary variable, identical values at different phases should be treated as positive instances. Furthermore, the phase must be represented in a way that accounts for its periodicity, as the values at the phase boundaries are equivalent. In this study, we evaluate CEBRA’s reconstruction performance on more complex latent structures driven by cyclic dynamics. To this end, we validate the method using both artificial data generated from Lorenz attractors and real heart rate data, exploring multiple auxiliary variable settings. In this presentation, we report the preliminary results of these validations.
[1-E-10] PDEの数値計算上のドメイン知識を組み込んだベイズPINNs
発表者 佐川遼 (大阪大学大学院情報科学研究科), 宮武勇登 (大阪大学サイバーメディアセンター), 降旗大介 (大阪大学サイバーメディアセンター)
概要 PINNsは、PDEの解をニューラルネットワーク(NN)で近似し、PDEや境界条件等の残差をNNの損失関数に設定して、その最適化問題を解くことで数値解を得る手法である。本研究では、ベイズNNを用いたB-PINNsを導入し、B-PINNsのパラメータの事前分布にPDEの数値計算上の条件等のドメイン知識を組み込むことで、NNの自由度を減らして数値計算の精度を向上させることを試みる。
[1-E-11] 時系列信号同期性に基づいた生成モデルによるクラスタ及び事後分布推定
発表者 武井悠 (茨城大), 木村俊 (群馬大), 竹田晃人 (茨城大)
概要 これまでに発表者らは,時系列信号である神経活動データから活動が同期するニューロン群である機能的神経クラスタの推定手法を取り扱ってきた.この手法では入力となる時系列信号をベイズ生成モデルにより表現しMCMC法により推定を行うが,クラスタ構造及びクラスタの時系列活動特徴の近似MAP解を求めるのみであった.そこで本発表では推定結果の信頼性を確認するために事後分布推定を試みた結果について述べる.
[1-E-12] CBF-LLM: LLMアライメントのための安全制御
発表者 宮岡佑弥 (慶應義塾大学), 井上正樹 (慶應義塾大学)
概要 本研究は,大規模言語モデル(LLM)をアライメントするための制御フレームワーク,CBF-LLMを提案する.CBF-LLM,LLMの推論内容にCBFベースの安全フィルタを介入させ,ユーザにとって好ましい文の生成を保証するものである.この手法の長所は,元のLLMを追加学習することなくアライメントできる点である.本発表では,Llama 3を元としたCBF-LLMの実装及び文の生成実験の結果を示す.
[1-E-13] αサブ指数分布における二値分類問題の良性過適合バウンドと学習率の条件
発表者 奥土康太 (慶應義塾大学), 小林景 (慶應義塾大学)
概要 ニューラルネットの発展に伴い、パラメータの数を増やしても過適合せず汎化性能が良くなる良性過適合という現象が現れている。本研究では、サブガウス分布を持つ二値分類問題における良性過適合を解析する。Chatterji and Long (2021)の問題設定を緩和し、従来のサブガウス分布に限定されたロジスティック回帰の良性過適合バウンドを、サブガウス分布より裾が重い分布に拡張した。また、その時の学習率の上界を導出した。
[1-E-14] One-Shot Domain Incremental Learning
発表者 江崎 泰志 (豊田中央研究所), 小出 智士 (豊田中央研究所), 沓名 拓郎 (豊田中央研究所)
概要 Domain incremental learning (DIL) has been discussed in previous studies on deep neural network models for classification. In DIL, we assume that samples on new domains are observed over time. The models must classify inputs on all domains. In practice, however, we may encounter a situation where we need to perform DIL under the constraint that the samples on the new domain are observed only infrequently. Therefore, in this study, we consider the extreme case where we have only one sample from the new domain, which we call one-shot DIL. We first empirically show that existing DIL methods do not work well in one-shot DIL. We have analyzed the reason for this failure through various investigations. According to our analysis, we clarify that the difficulty of one-shot DIL is caused by the statistics in the batch normalization layers. Therefore, we propose a technique regarding these statistics and demonstrate the effectiveness of our technique through experiments on open datasets.
[1-E-15] ドラレコデータと事故データを利用した運転挙動の異常検知
発表者 桑元凌 (三井住友海上火災保険株式会社), 後藤梨久都 (広島大学大学院), 桑田修平 (三井住友海上火災保険株式会社), 伊達賢志 (三井住友海上火災保険株式会社)
概要 損害保険会社が保持する事故データ、ドラレコの運転挙動データ(位置、速度、加速度等)を利用し、事故者と非事故集団の運転挙動に差がないか、を検証する。 今回、あるカーブ走行時において事故者と非事故集団を抽出し、事故者は同一地点において曲がりすぎている、ハンドルを早く切りすぎている等を検証する。 この取組みを通して、当社ドラレコへの事故防止アラートの実装や事故要因のさらなる特定を行い、事故防止につなげる。
[1-E-16] Echo State Network による乳牛の行動判別法の提案
発表者 村上 匠 (九州大学), 松田朝陽 (佐世保高専), 森野佳生 (九州大学)
概要 本発表では,酪農家の負担軽減という実課題の解決を目的として乳牛の行動を自動で判別するシステムの構築を試みた結果を報告する。乳牛の行動を学習・分類するモデルとしてRNNの一種である Echo State Network を採用した.分類精度向上のために,入力データである乳牛の行動を記録した動画を画像の時系列として変換する際に特定の前処理を行った結果,想定通りに乳牛の行動を少量のデータから高精度に学習・分類可能であることを示した.
[1-E-17] 新たな正規化された条件付相互共分散作用素による条件付独立性検定
発表者 宮崎隆之介 (一橋大学経済学部), 植松良公 (一橋大学ソーシャルデータサイエンス学部)
概要 正規化された条件付き相互共分散作用素を新たに定義し、その漸近正規性を確認することで新たな条件付き独立性検定を提案する。
[1-E-18] 対称性の発見によるダイナミクスの推定
発表者 後藤有輝 (慶應義塾大学/理研AIP)
概要 物理現象の背後にあるダイナミクスを学習し、予測する物理シミュレーションは、気象予測やロボット制御など、多くの応用がある。一方で、データに内在する対称性を学習により発見する手法が最近発展してきている。本ポスターでは、対称性の表現学習からダイナミクスを推定するアプローチについて、現段階における構想を共有し、参加者と想定される課題や周辺分野との関連性などを議論したい。
ポスターセッション2 [11月6日(水) 12:30 – 15:30] 発表一覧
レギュラー
[2-R-001] テンソル分解を用いた教師無し学習による変数選択法のバイオインフォマティクスへの応用
発表者 田口善弘 (中央大学)
概要 この度、表記の方法についてSpringerから2019年に出版した300頁の英文単著”Unsupervised Feature Extraction Applied to Bioinformatics”の第2版(500頁)を出版した[1]のを機に過去の研究を振り返り、研究内容を広く宣伝したい。 [1] https://www.growkudos.com/publications/10.1007%252F978-3-031-60982-4
[2-R-002] ガウス過程の転移学習
発表者 赤穂昭太郎 (産総研), 石橋英朗 (九工大)
概要 ガウス過程(GP)の転移学習の一手法を提案する.基本的な枠組みはターゲットとなるGPの精度が低い場合にソースGPの張る空間への射影を取ることで精度の向上を図る.GPの空間がm-平坦の時のみ consistent となることを示し,e-射影を取るアルゴリズムを提案する.GPは無限次元であるため,その座標を陽に扱うのは難しいが,KLダイバージェンスだけに依存した幾何学的アルゴリズムによって射影を求めることが可能となる.
[2-R-003] Optimistic Estimation of Convergence in Markov Chains with the Average-Mixing Time
発表者 WOLFER Geoffrey (早稲田大学), ALQUIER Pierre (ESSEC Business School)
概要 The convergence rate of a Markov chain to its stationary distribution is typically assessed using the concept of total variation mixing time. However, this worst-case measure often yields pessimistic estimates and is challenging to infer from observations. In this paper, we advocate for the use of the average-mixing time as a more optimistic and demonstrably easier-to-estimate alternative. We further illustrate its applicability across a range of settings, from two-point to countable spaces, and discuss some practical implications.
[2-R-004] Graph Community Augmentation with GMM-based Modeling in Latent Space (潜在空間における混合ガウスモデルに基づくモデリングによるグラフコミュニティ拡張)
発表者 福島真太朗 (トヨタ自動車株式会社), 山西健司 (東京大学)
概要 This study addresses the issue of graph generation with generative models. In particular, we are concerned with graph community augmentation problem, which refers to the problem of generating unseen or unfamiliar graphs with a new community out of the probability distribution estimated with a given graph dataset. The graph community augmentation means that the generated graphs have a new community. There is a chance of discovering an unseen but important structure of graphs with a new community, for example, in a social network such as a purchaser network. Graph community augmentation might also be helpful for generalization of data mining models in a case where it is difficult to collect real graph data enough. In fact, there are many ways to generate a new community in an existing graph. It is desirable to discover a new graph with a new community beyond the given graph while we keep the structure of the original graphs to some extent for the generated graphs to be realistic. To this end, we propose an algorithm called the graph community augmentation(GCA). The key ideas of GCA are (i) to fit Gaussian mixture model~(GMM) to data points in the latent space into which the nodes in the original graph are embedded, and (ii) to add data points in the new cluster in the latent space for generating a new community based on the minimum description length~(MDL) principle. We empirically demonstrate the effectiveness of GCA for generating graphs with a new community structure on synthetic and real datasets.
[2-R-005] Optimality of Deep Neural Features for Instrumental Variable Regression
発表者 Juno Kim (東京大学・理研), Zhu Li (GCNU, UCL), Dimitri Meunier (GCNU, UCL), Arthur Gretton (GCNU, UCL, Google Deepmind), Taiji Suzuki (東京大学・理研)
概要 We study the sample complexity and estimation error of the deep feature instrumental variables (DFIV) algorithm for IV regression using deep neural networks with smooth activations for both stages. We derive both projected and non-projected rates under link and smoothness conditions of the conditional mean embedding, and discuss when the minimax optimal rates are achieved.
[2-R-006] 構造的因果モデルに基づく観察データと実験データからの因果効果のベイズ推定
発表者 堀井俊佑 (早稲田大学), 近原鷹一 (NTT)
概要 本研究では、観察データと複数の実験データを用いて因果効果を推定するベイズ的手法を提案する。構造的因果モデル(SCM)に基づき、複数のデータセットから事後分布を算出し、因果効果の推定を行う。本手法は、ベイズ最適性を持ち、推定精度が高い点と、修飾因果効果も推定可能な点で従来手法より優れている。個別化医療や教育分野での少数データの問題にも対応できる点が特に有用である。
[2-R-007] アンサンブル学習における基礎理論の提唱
発表者 森下皓文 (日立製作所), 森尾学 (日立製作所), 堀口翔太 (日立製作所), 尾崎太亮 (日立製作所), 額賀信尾 (日立製作所)
概要 アンサンブル学習における基礎理論を提唱する.本理論は「どのような要因がアンサンブル手法の性能を決めるのか?」という根本的な問いに答える.情報理論に基づき,アンサンブル手法の誤差下限を導出し,その下限が「各モデルの精度」「モデルの予測群の多様性」「予測群を結合する際に生じる情報損失」の3要因に分解されることを示す.網羅的な実験により,本理論が様々なアンサンブル手法の性能を説明できることを示す.
[2-R-008] 辞書学習と一般化加法モデルを用いた船舶開発における重要流速成分の推定
発表者 大平祐生 (住友重機械工業)
概要 船舶開発では船舶周囲で生じる水流を分析し,高い推進性能を生み出す水の流れを発見することが重要となる.本研究ではシミュレーションにより得た水流及び推進性能値データを利用し重要成分の推定を行った.具体的には,辞書学習により複雑な水流から単純な水流特徴を抽出,それら特徴を入力とし一般化加法モデルによって性能値を予測させた.更に特徴と予測結果の関係を分析することで,重要流速成分候補を推定することができた.
[2-R-009] Stochastic Generative Scattering Network
発表者 荒木 貴光 (株式会社大塚商会 AI・IoTサポート課)
概要 Encoder-Decoder型の画像生成モデルであるGenerative Scattering Network (GSN)は,自然な画像を復元できるが,乱数を使った生成画像は不自然となる場合が多い.本発表では,Encoderの出力にガウス確率変数を加えてDecoderを学習するStochastic GSNを提案する.これにより,汎化が改善され,自然な画像の生成が可能となることを実験で確認する.
[2-R-010] Follow-the-Perturbed-Leader with Fréchet-type Tail Distributions: Optimality in Adversarial Bandits and Best-of-Both-Worlds
発表者 Jongyeong Lee (Seoul National University), Junya Honda (Kyoto University, RIKEN AIP), Shinji Ito (The University of Tokyo, RIKEN AIP), Min-hwan Oh (Seoul National University)
概要 This work studies the optimality of the Follow-the-Perturbed-Leader (FTPL) policy in both adversarial and stochastic K-armed bandits. Despite the widespread use of the Follow-the-Regularized-Leader (FTRL) framework with various choices of regularization, the FTPL framework, which relies on random perturbations, has not received much attention, despite its inherent simplicity. In adversarial bandits, there has been conjecture that FTPL could potentially achieve O(sqrt{KT}) regrets if perturbations follow a distribution with a Fréchet-type tail. Recent work by Honda et al. (2023) showed that FTPL with Fréchet distribution with shape alpha=2 indeed attains this bound and, notably logarithmic regret in stochastic bandits, meaning the Best-of-Both-Worlds (BOBW) capability of FTPL. However, this result only partly resolves the above conjecture because their analysis heavily relies on the specific form of the Fréchet distribution with this shape. In this work, we establish a sufficient condition for perturbations to achieve O(sqrt{KT}) regrets in the adversarial setting, which covers, e.g., Fréchet, Pareto, and Student-t distributions. We also demonstrate the BOBW achievability of FTPL with certain Fréchet-type tail distributions. Our results contribute not only to resolving existing conjectures through the lens of extreme value theory but also potentially offer insights into the effect of the regularization functions in FTRL through the mapping from FTPL to FTRL.
[2-R-011] Transformers are Universal In-context Learners
発表者 古屋貴士 (島根大学)
概要 Transformers are deep architectures that define “in-context mappings” which enable predicting new tokens based on a given set of tokens (such as a prompt in NLP applications or a set of patches for vision transformers). This work studies in particular the ability of these architectures to handle an arbitrarily large number of context tokens. To mathematically and uniformly address the expressivity of these architectures, we consider the case that the mappings are conditioned on a context represented by a probability distribution of tokens (discrete for a finite number of tokens). The related notion of smoothness corresponds to continuity in terms of the Wasserstein distance between these contexts. We demonstrate that deep transformers are universal and can approximate continuous in-context mappings to arbitrary precision, uniformly over compact token domains. A key aspect of our results, compared to existing findings, is that for a fixed precision, a single transformer can operate on an arbitrary (even infinite) number of tokens. Additionally, it operates with a fixed embedding dimension of tokens (this dimension does not increase with precision) and a fixed number of heads (proportional to the dimension). The use of MLP layers between multi-head attention layers is also explicitly controlled.
[2-R-012] Methods for Improving the Lack of Flexibility and Generality in Rotation-based Knowledge Graph Embedding
発表者 Zhu Yihua (Kyoto University, RIKEN AIP), Hidetoshi Shimodaira (Kyoto University, RIKEN AIP)
概要 The primary goal of Knowledge Graph Embeddings (KGE) is to learn low-dimensional representations of entities and relations for predicting missing facts. While rotation-based methods such as RotatE and QuatE have demonstrated strong performance in KGE tasks, they encounter two key challenges: limited flexibility, as the relation size must scale proportionally with entity dimensions, and difficulty in generalizing to higher-dimensional rotations. To overcome these limitations, we propose a novel KGE model that represents entities with matrices and utilizes block-diagonal orthogonal matrices for relations, optimized using Riemannian optimization. This method not only improves the generality and flexibility of KGE models but also effectively captures the relational patterns identified by rotation-based methods.
[2-R-013] Symmetry Breaking in Parallelized MLP-Mixer
発表者 太田敏博 (サイバーエージェント)
概要 Transformers have established themselves as the leading neural network model in natural language processing and are increasingly foundational in various domains. In vision, the MLP-Mixer model has demonstrated competitive performance, suggesting that attention mechanisms might not be indispensable. Inspired by this, recent research has explored replacing attention modules with other mechanisms, including those described by MetaFormers. However, the theoretical framework for these models remains underdeveloped. We propose a novel perspective by integrating Krotov’s hierarchical associative memory with MetaFormers, enabling a comprehensive representation of the entire Transformer block, encompassing token-/channel-mixing modules, layer normalization, and skip connections, as a single Hopfield network. This approach yields a parallelized MLP-Mixer derived from a three-layer Hopfield network, which naturally incorporates symmetric token-/channel-mixing modules and layer normalization. Empirical studies reveal that symmetric interaction matrices in the model hinder performance in image recognition tasks. Introducing symmetry-breaking effects transitions the performance of the symmetric parallelized MLP-Mixer to that of the vanilla MLP-Mixer. This indicates that during standard training, weight matrices of the vanilla MLP-Mixer spontaneously acquire a symmetry-breaking configuration, enhancing their effectiveness.
[2-R-014] Last Iterate Convergence in Monotone Mean Field Games
発表者 磯部伸 (東京大学), 阿部拳之 (サイバーエージェント), 蟻生開人 (サイバーエージェント)
概要 平均場ゲームは,大規模なマルチエージェント環境を近似するためのモデルである. 平均場ゲームのナッシュ均衡を近似計算する手法は多く提案されているが,これらは学習される戦略の,時間平均に対する収束性しか保証されていない. 本研究では,適応的なKL正則化によって学習を安定化させた手法を提案する. 提案手法においては,報酬の弱単調性の仮定の下で,学習される戦略そのものの均衡への収束性が理論的に示される.
[2-R-015] 説明付き2層ReLUネットワークへのモデル復元攻撃の数値評価
発表者 三浦尭之 (NTT社会情報研究所), 岩花一輝 (NTT社会情報研究所), 芝原俊樹 (NTT社会情報研究所)
概要 MilliらはFAT19にてVanilla Gradientという勾配による説明がついた2層のReLUニューラルネットワークを入出力から盗むのに必要なクエリのオーダーを理論的に導出した.しかし,これらは理論評価にとどまっており,実際にどの程度のクエリが具体的に必要なのかは明らかになっていなかった.本研究はMilliらの手法を実装し,具体的なクエリ量を数値評価した.また,実装を通し,論文では検討されていない新たな問題点を明らかにし,その解決策を提案した.
[2-R-016] クライアントの特徴データ抽出を行う連合学習法の検討
発表者 河野駿介 (静岡大学), 山本泰生 (静岡大学), 梶大介 (株式会社デンソー)
概要 分散データの学習手法に連合学習 (federated learning) が存在する.連合学習はモデルを集約し平均して最適化を行うため,独立同分布に従わない固有データの特徴づけが難しい.本研究では全データ対応の一般モデルに加え,クライアント固有データ対応の個別モデルを用い,特徴データを考慮した学習手法を提案する.また,各データに対する独自性を定義し,特徴データを抽出する.評価実験より特徴データの抽出と分析を行い,提案手法の有効性を示す.
[2-R-017] Transformerの特性を利用した列対称関数の近似
発表者 竹下 直樹(東京大学大学院、総合文化研究科), 今泉允聡 (東京大学)
概要 Transformerは、ReLU FNN 等のニューラルネットワークの拡張で、数学的には行列から行列への写像と定義される。これまで研究されてきたReLU FNNの関数近似の性質を活用した、Transformerの関数近似の研究も進んでいる。本研究では、対称式の概念を活用し、パラメータ数が入力行列の列数(=入力データ数)とは独立というTransformerの特性を活かした関数近似を構成した。
[2-R-018] 視覚言語モデルを用いたスプリアス相関の低減における欠損グループへの汎化
発表者 下坂知広 (筑波大学/理研AIP), 福地一斗 (筑波大学/理研AIP)
概要 機械学習モデルの頑健性を高める上で、スプリアス相関の学習を防ぐことは重要である。既存研究の手法には欠損グループ存在下における観測グループが持つスプリアス相関と、未定義グループが持つスプリアス相関の学習を防げないという問題がある。本発表では視覚言語モデルを用いることで欠損グループの有無に関わらず、任意のスプリアス相関の影響を低減する手法を紹介し、スプリアス相関に対する頑健性が向上することを示す。
[2-R-019] 平面領域内の2点間の距離を非ユークリッド距離で測ったときの分布の計算
発表者 岩田一貴 (広島市立大学)
概要 平面の凸領域内から選ぶあらゆる2点間の移動の長さを何らかの距離で測ることで、領域についての距離の分布が得られる。分布は領域の形に依存し、合同変換に対して不変であるから、形の解析に応用できる。この発表では、いくつかの非ユークリッド距離で測ったときの分布を、直線の集合の密度を用いた式で表現する。直線の集合を生成することにより、この式は分布の和として効率的に計算できる。
[2-R-020] 縮小ランク回帰における局所学習係数推定手法のモデル選択への応用
発表者 林 直輝 (株式会社豊田中央研究所), 沓名 拓郎 (株式会社豊田中央研究所), 名取 直毅 (株式会社アイシン)
概要 特異学習理論に基づく深層神経回路網モデル解析手法が提案されている.先行研究では確率的Langevin力学(SGLD)を用いて局所事後分布を実現し,スケーラブルな計算を実現していたが,モデル選択は行われていなかった.本発表では特異学習理論に基づく深層神経回路網モデル選択手法構築のための基礎として,SGLDの正確性検証のために,縮小ランク回帰を対象にWAICやWBIC及び実対数閾値の推定量を用いたモデル選択の数値実験結果を報告する.
[2-R-021] Evaluation of Best-of-N Sampling Strategies for Language Model Alignment
発表者 市原有生希 (NAIST, ATR), 陣内佑 (サイバーエージェント), 森村哲郎 (サイバーエージェント), 阿部拳之 (サイバーエージェント), 蟻生開人 (サイバーエージェント), 坂本充生 (サイバーエージェント), 内部英治 (ATR)
概要 Best-of-N (BoN) サンプリングは,言語モデルを人間の選好に合わせる効果的な手法だが,与えられた報酬関数に過適合してしまう問題がある.先行研究ではBoN サンプリングにおける正則化の有効性が実験的に示されたが,良い性能をもたらす理由は不明確であった.本研究では,BoN サンプリングにおける正則化がロバスト最適化に対応し,ある範囲内での最悪の報酬を最大化することを示す.
[2-R-022] 深層ハイブリッドモデルとその研究開発への適用にむけて
発表者 武石 直也 (東京大学)
概要 機械学習モデルと数理モデルを組み合わせたハイブリッドモデルは、学習効率、外挿的予測性能、解釈性の向上などのために注目されてきた。深層学習が科学研究や技術開発でも活用されるなかで、深層ニューラルネットに基づくハイブリッドモデルが有用だと期待される。しかし、研究開発に用いるうえではパラメタの識別不可能性などの課題がある。本発表では、深層ハイブリッドモデルを適切に学習する方法について議論する。
[2-R-023] リアプノフ指数をフラクタル図形で表現する試案
発表者 城真範 (産総研)
概要 ポアンカレプロットは決定論性を示す図、リカレンスプロットは周期点を示す図である。いずれも決定論的カオスの表現方法として有効でありよく使われている。ここではリアプノフ指数を表現する方法と円形状のプロットを提案する。差を指数化したプロットという点ではリカレンスプロットの一種かもしれない。リアプノフ指数のパターンもまたカオスを特徴づける。
[2-R-024] モジュラリティ最大化に基づいた線形次元削減手法
発表者 増田伊吹 (筑波大学), 二村保徳 (筑波大学), Jianbo Lin (物質・材料研究機構), Anh Khoa Augustin Lu (東京大学), 田村亮 (物質・材料研究機構), 宮崎剛 (物質・材料研究機構), 櫻井鉄也 (筑波大学)
概要 モジュラリティはグラフにおける頂点集合の分割の質を表す指標の一つであり、ネットワーク上のコミュニティ検出において広く用いられている。本研究では高次元データ間の類似度を表すグラフのモジュラリティ最大化に基づいた低次元表現をモジュラリティ行列の固有値計算によって得る手法を提案する。また、グラフラプラシアンに基づく次元削減手法との関連性とそれぞれの性質について考察する。
[2-R-025] 自由エネルギー原理に基づく楽観・悲観バイアスのデータ駆動的解読
発表者 東野伊織 (広島大学), 横山寛 (滋賀大学), 伊東諒 (京都大学), 加藤利佳子 (京都大学), 雨森賢一 (京都大学), 本田直樹 (名古屋大学)
概要 我々は、リスクを取る際に楽観・悲観のバイアスが生じている。しかし、従来の研究では、楽観・悲観を定性的にしか表現できていないがために、そのメカニズムも未解明である。そこで本研究では脳が変分自由エネルギー(負の対数周辺尤度の上限)を最小化するように学習・行動しているという自由エネルギー原理に基づき、楽観・悲観バイアスを導入した数理モデルを構築し、猿の行動データから楽観・悲観バイアスの定量化を行った。
[2-R-026] 混合整数線形計画における目的関数の重みを決定する高速な逆最適化アルゴリズム
発表者 北岡 旦 (NEC)
概要 例えば混合整数線形計画において,解が与えられたとき,その解が最適解になるような目的関数の重みを決定する問題を考える.この問題を解くのに,従来の方法だと,高次元の場合で計算効率が悪い.本発表では,suboptimality損失に対する,更新幅を(反復回数)^(-1/2)とする射影劣勾配法を適応することにより,この問題を高次元でも有限回の反復で,効率的に解けることを理論的側面と実験的側面から解説する.
[2-R-027] 修正オフセットノイズを用いた汎用拡散モデル
発表者 沓名拓郎 (株式会社豊田中央研究所)
概要 拡散モデルには極端な輝度の画像が生成されにくいという課題がある。この課題に対処する方法の一つにオフセットノイズがあり、実験的に有効性が確認されているが、その理論的な正当性は示されていない。本研究では、オフセットノイズと類似したロス関数が理論的に導出される、新たな拡散モデルを提案する。提案モデルは、任意の平均構造をもつ正規分布へと入力を拡散させるものであり、既存モデルの一般化となっていることを示す。
[2-R-028] Optimal Memorization Capacity of Transformers
発表者 梶塚時央 (東京大学), 佐藤一誠 (東京大学)
概要 Recent research in the field of machine learning has increasingly focused on the memorization capacity of Transformers, but how efficient they are is not yet well understood. We demonstrate that Transformers can memorize labels with $\tilde{O}(\sqrt{N})$ parameters in a next-token prediction setting for $N$ input sequences of length $n$, which is proved to be optimal up to logarithmic factors. This indicates that Transformers can efficiently perform memorization with little influence from the input length $n$ owing to the benefit of parameter sharing. We also analyze the memorization capacity in the sequence-to-sequence setting, and find that $\tilde{O}(\sqrt{nN})$ parameters are not only sufficient, but also necessary at least for Transformers with hardmax. These results suggest that while self-attention mechanisms can efficiently identify input sequences, the feed-forward network becomes a bottleneck when associating a label to each token.
[2-R-029] Open-set Recognition by Dirichlet Posterior Uncertainty
発表者 chen zhaozhi (京都大学), 田中 利幸 (京都大学)
概要 Open-set recognition is a topic that aims to build a model that can not only classify samples from known classes but also detect samples from unknown classes. A core factor in open-set recognition lies in whether the algorithm can correctly classify a sample from a known class and correctly reject a sample from an unknown class. The difficulty in open-set recognition is that there are no available samples from unknown classes so an open-set classifier is hard to train. We propose a method to estimate, as the novelty score, the confidence of a classification system based on the Dirichlet posterior for input samples, which provides information on how uncertain a sample is belonging to a known class. On the other hand, conventional open-set recognition is achieved by treating the problem as a one-class classification problem, which makes it difficult to classify samples from multiple known classes. The proposed method can address this problem by using the property of the Dirichlet posterior, without additional steps to perform the multi-class classification task.
[2-R-030] Multi-objective Good Arm Identification with Bandit Feedback
発表者 Xuanke Jiang (Kyushu University/RIKEN AIP), Kohei Hatano (Kyushu University/RIKEN AIP), Eiji Takimoto (Kyushu University)
概要 We consider a good arm identification problem in a stochastic bandit setting, where each arm returns a reward vector when pulled, and an arm is good if each component of the expected reward vector is above a given threshold. We propose an algorithm with theoretical guarantees.
[2-R-031] Group Symmetry Decomposition for on-Manifold Extrapolation
発表者 荒井勇人 (東京大学), 小山雅典 (Preferred Networks), 林浩平 (Preferred Networks), 福水健次 (統計数理研究所)
概要 対称性をもったデータの表現学習問題に対し、対称性による変換を潜在空間上の線形変換として教師なし学習で実現する手法(NFT, NISO)が近年考案されている。これらの手法はサンプルデータに含まれる変換を自動的に獲得し、それらの積による変換の外挿を可能とする。本研究では群論的な直積分解を用いて、許される変換全体の空間の座標軸を学習することで、より広い範囲の変換を外挿できることを示す。
[2-R-032] Orbifold 座標によるニューラルネットワークの順列不変性の除去
発表者 大塚瑛介 (東北大学), 菅野尚哉 (アイシン・ソフトウェア) , 末武一馬 (アイシン・ソフトウェア)
概要 ニューラルネットワークはニューロンの置換に対する対称性である順列不変性を持っており、冗長性の観点からこの順列不変性が障害となりモデル間の比較が難しくなる。そこで我々は、重みパラメタ空間の順列不変性による商空間である orbifold を用いてニューラルネットワークを再構築した orbifold neural network を提案する。さらに、モデルスープや汎化誤差解析への応用例を議論する。
[2-R-033] ロバストな半教師あり異常検知のためのPositive-Unlabeled Autoencoder
発表者 高橋大志 (NTT), 岩田具治 (NTT), 熊谷充敏 (NTT), 山中友貴 (NTT)
概要 半教師あり異常検知は、ラベルなしデータに加えて少量の異常データを用いて検出性能の向上を目指している。しかし、既存手法はラベルなしデータを全て正常データと仮定するため、異常データが含まれていると性能が低下する。本研究では、このような汚染されたラベルなしデータにも対応可能な半教師あり異常検知手法であるPositive-Unlabeled Autoencoderを提案する。
[2-R-034] 制限ボルツマンマシン上の高性能な最大周辺確率推定
発表者 関本快士 (山形大学), 安田宗樹 (山形大学)
概要 制限ボルツマンマシンにおいて、データ分布に対応する周辺分布の最大確率推定は種々の推定問題で重要となる。確率最大化の常套である焼きなまし法は、目的の周辺分布からのサンプリングを要するが、これは周辺化前の結合分布からのサンプリングよりも扱いにくい。そこで、結合分布からのサンプリングと同様の容易さをもつ新しい焼きなまし法を提案する。提案法は単純な焼きなまし法よりも扱いやすく、更に、高い推定性能を示す。
[2-R-035] 大規模データ学習に向けたスケーラブルなノイズ拡張カーネル法:タニモトカーネルとガウスカーネルの性能比較研究
発表者 CHEN MINRUI (九州大学), 西郷浩人 (九州大学)
概要 本研究は、大規模データにおける学習性能とクラスタリング精度向上を目的に、タニモトカーネルとガウスカーネルのスケーラブルな拡張を比較します。 特に、カーネルにノイズ項を導入し、分類、回帰、クラスタリングタスクの性能を改善します。 使用するデータセットには、UCIデータセットおよびscikit-learnデータセットを用いて、多様なタスクに対応するモデルを評価し、タニモトカーネルの特性や新しいカーネルの優位性を示します。
[2-R-036] 疑似相関の優先的獲得がもたらすニューラルネットワークの特徴量学習の遅延メカニズム
発表者 渡邉大師 (京都大学), 寺前順之介 (京都大学)
概要 ニューラルネットワークは、分類タスクにおいてクラスラベルとの疑似相関をもつ単純な特徴量を優先して学習し、誤分類を引き起こすことが知られているが、この学習のダイナミクスにおけるそのメカニズムは未解明の部分が多い。本研究では、二層線形ニューラルネットワークの学習ダイナミクスを解析し、疑似相関の学習後にしか真の特徴量の学習が進まないという学習の段階的特性がこの問題の主要因であることを示す。
[2-R-037] インコンテキスト学習におけるTransformerの自動ドメイン適応
発表者 幡谷龍一郎 (理研AIP), 松井孝太 (名古屋大学,理研AIP), 今泉允聡 (東京大学,理研AIP)
概要 本発表ではTransformerのインコンテキスト学習が,重要度重み付き学習やドメイン敵対的ニューラルネットワークといった転移学習アルゴリズムと,さらに与えられたデータの性質に応じて自動的にそれらの手法を切り替えるアルゴリズムを近似できることを示す.
[2-R-038] NTK理論によるLP-FT手法の理解
発表者 富張 聡祥 (東京大学), 佐藤 一誠 (東京大学)
概要 The two-stage fine-tuning (FT) method, linear probing then fine-tuning (LP-FT), consistently outperforms linear probing (LP) and FT alone in terms of accuracy for both in-distribution (ID) and out-of-distribution (OOD) data. This success is largely attributed to the preservation of pre-trained features, achieved through a near-optimal linear head obtained during LP. However, despite the widespread use of large language models, the exploration of complex architectures such as Transformers remains limited. In this paper, we analyze the training dynamics of LP-FT for classification models on the basis of the neural tangent kernel (NTK) theory. Our analysis decomposes the NTK matrix into two components, highlighting the importance of the linear head norm alongside the prediction accuracy at the start of the FT stage. We also observe a significant increase in the linear head norm during LP, stemming from training with the cross-entropy (CE) loss, which effectively minimizes feature changes. Furthermore, we find that this increased norm can adversely affect model calibration, a challenge that can be addressed by temperature scaling. Additionally, we extend our analysis with the NTK to the low-rank adaptation (LoRA) method and validate its effectiveness. Our experiments with a Transformer-based model on natural language processing tasks across multiple benchmarks confirm our theoretical analysis and demonstrate the effectiveness of LP-FT in fine-tuning language models.
[2-R-039] 固定予算及び固定信頼度設定下でのリスク回避型多目的バンディット
発表者 野永竣太 (北大電子研), 田畑公次 (北大電子研), 水野雄太 (北大電子研), 小松崎民樹 (北大電子研)
概要 多腕バンディットにおける従来の最適腕識別は期待報酬が最大となる腕の識別を目的としているが、実際の応用では報酬の不確実性も重要である。本研究では、期待報酬に加え、報酬分散などのリスク指標を考慮し、リスク回避的な最適腕集合を効率的に列挙するアルゴリズムを提案する。固定予算設定では単純リグレットを、固定信頼度設定ではサンプル複雑性を基準にアルゴリズムの性能を評価し、それぞれのケースでの有効性を実証した。
[2-R-040] データ分析パイプラインによる特徴選択に対する統計的仮説検定
発表者 白石智洸 (名大), 松川竜也 (名大), 西納修一 (名大/理研), 竹内一郎 (名大/理研)
概要 データに複数アルゴリズムを多段に適用し知見を得ることが広く行われているが,得られた知見の統計的有意性は自明ではない.本研究では表データを入力とし,複数の欠損値補完法・外れ値除去法・特徴選択法を任意に組み合わせた回帰分析パイプラインが出力する特徴への検定手法を提案する.Selective Inferenceの枠組みにより理論的にFPRを指定水準に制御可能で,パイプラインの自動最適化にも対応する.
[2-R-041] 特定健診データに対するエネルギー地形解析
発表者 稲葉 晴紀 (富山大学大学院理工学研究科), 小久保 茉由 (富山大学大学院理工学研究科), 戸邉 一之 (富山大学附属病院第一内科・富山大学未病研究センター), 奥 牧人 (富山大学学術研究部教育研究推進系・富山大学未病研究センター), 四方 雅隆 (富山大学附属病院第一内科), 春木 孝之 (富山大学学術研究部都市デザイン学系・富山大学未病研究センター), 木村 巌 (富山大学学術研究部理学系・富山大学未病研究センター), 永田 義毅 (一般財団法人 北陸予防医学協会 予防医学研究室), 山上 孝司 (一般財団法人 北陸予防医学協会 予防医学研究室), 上田 肇一 (富山大学学術研究部理学系・富山大学未病研究センター)
概要 エネルギー地形解析とは,多次元時系列に見られる状態間遷移をグラフ化する手 法である。本研究では,富山県の特定健診データに対してエネルギー地形解析を行い, 健康状態の悪化における特徴的な遷移過程とその性別による違いを解析した。
[2-R-042] 比例的高次元レジームの線形モデルにおける順位型損失の漸近解析
発表者 澤谷一磨 (東京大学), 植松良公 (一橋大学), 今泉允聡 (東京大学,理研AIP)
概要 本研究では,サンプルサイズと特徴量の次元が比例的に発散する高次元領域において, 順位統計量に基づく損失関数最小化から得られる回帰推定量の漸近挙動を導く. 古典的には漸近相対効率性の観点から理想的なロバスト性が知られ, チューニングフリー・モーメントフリー特性をもつ順位型損失最小化が, 高次元性の程度に応じてどのような挙動を示すのかを明らかにする.
[2-R-043] (不完全情報)展開型ゲームにおける零分散の利得摂動手法
発表者 眞坂航宙 (電気通信大学), 坂本充生 (サイバーエージェント), 阿部拳之 (サイバーエージェント, 電気通信大学大学院), 蟻生開人 (サイバーエージェント), 岩崎敦 (電気通信大学大学院)
概要 ゲームの均衡学習では,摂動させた利得関数を用いて学習を安定化させる手法が一般的である.ポーカーのような膨大な状態数を持つ展開型ゲームでは,各反復ごとに一部の履歴をサンプルし戦略を更新することで計算量を削減するアプローチが典型的に取られるが,適した利得の摂動手法は未だに明らかになっていない. 本研究では既存手法に加え新たに零分散の摂動手法を提案し,展開型ゲームの学習に適した利得の摂動方法を比較する.
[2-R-044] ガウス過程回帰モデルによるテスト分布を考慮した能動学習
発表者 大藏芳斗 (名古屋大学), 竹野思温 (名古屋大学/理化学研究所), 稲津佑 (名古屋工業大学), 青山竜也 (名古屋大学), 田中智成 (名古屋大学), 赤羽智志 (名古屋大学), 花田博幸 (理化学研究所), 橋本典明 (理化学研究所), 村山太朗 (株式会社デンソー), 李翰柱 (株式会社デンソー), 小嶋信矢 (株式会社デンソー), 竹内一郎 (名古屋大学/理化学研究所)
概要 能動学習は適応的にデータを収集することで少ないデータ数で予測精度の高いモデルを構築する手法である.通常,能動学習では全ての候補に対して一様に予測精度を高めるようにデータを収集する.一方,実践的にはテスト時のデータ分布が一様でない未知の分布である場合が多い.本研究では,ガウス過程回帰モデルを用いた未知のテスト分布に対して有効な能動学習手法を提案し,画像分類問題に対する実験を通じてその性能を評価する.
[2-R-045] Improvement of SPAR-SINK by modifying the sampling probability matrix
発表者 伊藤尚紀 (電気通信大学大学院), 前田煌 (電気通信大学), 西山悠 (電気通信大学大学院)
概要 Sinkhorn algorithm offers an efficient approach for solving entropic optimal transport problems. However, its practical application is often limited by its computational complexity of $O(n^2)$ for a sample size $n$, motivating research aimed at accelerating its convergence rate. One such approach, known as \textsc{Spar-Sink} (M. Li et al., JMLR 2023), approximates the Gibbs kernel matrix sparsely, reducing the computational burden per iteration to $\widetilde{O}(n)$ while maintaining the same number of iterations required for convergence. In this work, we propose an enhancement to this method by incorporating information from the cost matrix into the sampling probability matrix. This adjustment allows for a selection of more informed elements, leading to improved stability and precision. Additionally, we introduce an iterative sampling strategy for the Gibbs kernel matrix, which reduces the noise introduced by sparsity. Through comparative experiments, we demonstrate that both the proposed method and the iterative sampling outperform the original \textsc{Spar-Sink} method in terms of both computational stability and solution accuracy.
[2-R-046] 確率微分方程式の学習において物理モデルおよび正則化を導入する効果の検証
発表者 大坂光 (東京大学), 武石直也 (東京大学), 矢入健久 (東京大学)
概要 確率微分方程式を学習することは確率システムの制御を構築する上で重要である.その際,物理モデルを組込むことでモデルの汎化性能やロバスト性向上が期待される.一方で訓練時に物理モデルの情報を効果的に活用するためには,ニューラルネットの出力に制約を加える正則化が必要であると考えられる.本研究では,物理モデルや正則化の導入が外挿性能や訓練データが少ない場合のモデル化性能向上に貢献するか,実験を行い検証する.
[2-R-047] Fixed Confidence Best Arm Identification in the Bayesian Setting
発表者 Kyoungseok Jang (Universitá degli Studi di Milano), Junpei Komiyama (New York University, RIKEN AIP), Kazutoshi Yamazaki (The University of Queensland)
概要 We consider the fixed-confidence best arm identification (FC-BAI) problem in the Bayesian setting. This problem aims to find the arm of the largest mean with a fixed confidence level when the bandit model has been sampled from the known prior. Most studies on the FC-BAI problem have been conducted in the frequentist setting, where the bandit model is predetermined before the game starts. We show that the traditional FC-BAI algorithms studied in the frequentist setting, such as track-and-stop and top-two algorithms, result in arbitrarily suboptimal performances in the Bayesian setting. We also obtain a lower bound of the expected number of samples in the Bayesian setting and introduce a variant of successive elimination that has a matching performance with the lower bound up to a logarithmic factor. Simulations verify the theoretical results.
[2-R-048] Symplecticガウス過程を用いたハミルトニアンモンテカルロ法の高速化
発表者 柏村周平 (東京大学), 田中佑典 (NTT)
概要 マルコフ連鎖モンテカルロ法(MCMC)は目的の分布に収束するようなマルコフ連鎖のシュミレートにより分布からのサンプルを取得することができる.一方で,確率密度の評価に要する計算コストが大きい場合,MCMCの計算量も増大する.本発表では,MCMCの中でもハミルトニアンモンテカルロ法に注目し,計算が重い演算の一部を学習モデルでサロゲートする手法に注目する.物理制約をガウス過程に課したSymplecticガウス過程によるサロゲートが他手法より優れていることを示す.
[2-R-049] X線回折強度を条件付けした拡散生成モデルによる結晶構造生成
発表者 塚上賢太 (名古屋大学大学院情報学研究科複雑系科学専攻)
概要 画像生成で用いられる拡散モデルを物質の生成に応用し、X線回折強度を条件として結晶構造を生成する手法を提案する。従来、画像生成ではラベル学習を用いた条件付をするが、Tweedy formulaに基づく学習不要な条件付も注目されている。物質構造は既知の結晶構造を参考に決定されるため、本研究では既知の結晶構造データを学習した拡散モデルにラベル学習なしで回折強度を条件付し結晶構造を生成する手法を開発する。
[2-R-050] Vision-Language Model における人物属性にもとづく嗜好の偏り
発表者 熊谷雄介 (株式会社博報堂DYホールディングス), 馬場雪乃 (東京大学)
概要 Vision-Language Model (VLM) は大規模な画像・言語コーパスから学習された視覚と言語を同時に扱う基盤モデルである.VLM は学習により「好ましさ」を獲得しているが,その価値観や嗜好は明らかではない.本研究では顔画像を用いた一対比較実験を通じて VLM における嗜好の偏りを明らかにする.結果,VLM は 男性と女性など複数の属性ペアにて有意に一方を好むことが示された.
[2-R-051] 深層学習モデルが示す重要領域に対する信頼性評価手法の開発
発表者 勝岡輝行 (名古屋大学), 白石智洸 (名古屋大学), 西納修一 (名古屋大学), 竹内一郎 (名古屋大学,理研)
概要 CAM等のXAIや,VAEによる再構成ベースの異常検知などは入力画像中の重要領域を示す技術と解釈できる.しかし,示された領域が必ずしも意味を持つとは限らない.そのため,領域の有意性を評価することはAIの信頼性に関わる重要な課題である.本研究では選択的推論を用いて,一般的な深層学習フレームワークで構築されたモデルに対して有効な仮説検定が容易に行える手法を開発し,Pythonパッケージとして公開する.
[2-R-052] 二値応答と選好情報を活用するベイズ最適化
発表者 栗聡汰 (名古屋大学), 竹野思温 (名古屋大学, 理化学研究所), 稲津佑 (名古屋工業大学), 竹内一郎 (名古屋大学, 理化学研究所)
概要 ベイズ最適化は高コストな実験から得られる実数値情報を逐次的に観測することで効率的なブラックボックス最適化を目指す. しかし, 試験紙の反応の有無といった二値応答情報が得られる実験も存在する. また, 専門家が2つの候補からどちらが優れているかを判断する選好情報が得られる場合も数多い. 本研究では, これらの情報源を統一的に活用するベイズ最適化法を提案し, 数値実験によって有効性を検証する.
[2-R-053] Diffusion Modelsにおける画像生成確率の定量的評価
発表者 長谷川将弥 (名古屋大学大学院情報学研究科複雑系科学専攻)
概要 画像生成モデルはデータセットに含まれる画像を生成する場合があり、著作権保護の観点で問題を抱えている。本研究ではDiffusion Modelsでの画像の生成されやすさを定量的に評価する。ある学習画像は拡散過程でノイズ画像に射影されるが、その体積は逆拡散過程での当該画像の生成確率を決める。この性質を利用し、体積の広がりやすさによって生成確率の定量化を目指す。
[2-R-054] 強化学習への敵対的サンプルに対する将来予測を用いた防御手法の提案
発表者 後藤 勇芽輝 (大阪大学大学院情報科学研究科), 河原 吉伸 (大阪大学大学院情報科学研究科)
概要 強化学習は, ノイズを混入させることで推論を誤らせる敵対的例に脆弱である. さらに, 近年特定の状態のみ攻撃することで攻撃コストを減らす現実的な攻撃が提案され脅威となっている. 防御手法として, 入力が敵対的例であるかを検証する防御手法が提案されているが計算がコスト上現実的ではない. 本研究では, 将来予測を行うことでエージェントの未来の状態について頑強性を担保する, オンライン学習可能な敵対的サンプルに対する防御手法を提案する.
[2-R-055] 高速かつノンパラメトリックな一般化加法モデル学習を用いた関数データ回帰
発表者 武田優真 (東京大学), 松島慎 (東京大学)
概要 Function-on-scalar (FOS) 回帰とはスカラーな独立変数から関数形の従属変数を予測するために用いられる回帰手法であり、医療データ分析などで有用性が認められている。FOS回帰は従来、計算コストの高さやパラメトリックな学習に伴う性能の限界があった。本研究では、これらの課題を解決するため、一般化加法モデルを基にした新たな学習手法を提案し、より効率的かつ柔軟な FOS 回帰を実現した。
[2-R-056] データ重要度評価に基づく能動学習を用いた音声合成
発表者 関 健太郎 (東大), 高道 慎之介(慶大/東大), 佐伯 高明(東大), 猿渡洋 (東大)
概要 近年、音声合成モデルの学習に用いるデータセットの規模が加速度的に増加しており、学習効率改善が重要となっている。そこで本研究では、データ収集とモデル学習を反復してモデル性能を改善する能動学習の枠組みに注目する。提案手法は「どのデータで音声合成モデルを学習すべきか?」というデータ重要度評価に基づいてデータセットを拡張することで、データセットサイズに対し効率的な学習を実現する。
[2-R-057] 系列データに対する潜在変数を用いた連続緩和に基づくベイズ最適化
発表者 田中優次 (名古屋大学), 竹野思温 (名古屋大学,理化学研究所), 増田慎太郎 (名古屋工業大学), 稲津佑 (名古屋工業大学), 烏山昌幸 (名古屋工業大学), 永田崇 (東京大学), 井上圭一 (東京大学), 竹内一郎 (名古屋大学,理化学研究所)
概要 ベイズ最適化はサンプル効率の高いブラックボックス最適化を目指す. しかし, 系列データに対してはNP-hardな離散最適化がアルゴリズム内で必要とされてしまう. 本研究では, 系列データで学習された生成モデルの潜在変数を用いて離散最適化を連続最適化に緩和するベイズ最適化法を提案する. 最後に, タンパク質の改変に関する模擬実験を含む数値実験を通じて提案手法の有効性を検証する.
[2-R-058] 可逆なデータ拡張を用いるGANの学習アルゴリズムと汎化誤差解析
発表者 小池由能 (東京科学大), 中川匠 (東京科学大,理研), 和井田博貴 (東京科学大), 金森 敬文 (東京科学大,理研)
概要 生成モデルの学習アルゴリズムであるGANにおけるデータ拡張の効果について報告する.Diffusion-GANでは拡散過程をデータ拡張として利用する.本研究では拡散過程におけるノイズとスケーリングについて考察し,スケーリングが学習の安定化と高品質なデータ生成に重要であることを理論と数値実験により示す.さらに,一般の可逆なデータ拡張を用いるGANについて理論的に検討した結果を紹介する.
[2-R-059] LLMによる教材生成とモニタリング機構を備えた学習支援システム
発表者 下斗米貴之 (株式会社ヘッドウォータース)
概要 学習支援とその効率化は、教育現場や組織で必要とされています。本研究では、LLMを使用した統合的な適応型テスト・学習支援システムを提案します。学習者個人に最適な学習経路を提供し、項目応答理論と粒子フィルタを用いて能力モニタリングし、能力を元にした教材推薦により学習効果を最適化します。LLMを用いた教材・問題生成と持続的なモニタリング機構により、コールドスタート問題を緩和し、個別指導の自動化に貢献することが期待されます。
[2-R-060] 主成分分析の物理的意味
発表者 堀池由朗 (名古屋大学/University of Copenhagen), 藤城新 (京都大学), 笹井理生 (京都大学/名古屋大学)
概要 教師なし機械学習として知られる主成分分析は、統計学・深層学習の分野でデータの可視化、次元削減などにしばしば用いられる定番の手法である。主成分には共分散を最大化する軸という意味があり、固有値には主成分により表現された共分散という意味があることが知られている。しかし、それ以上の解釈を得られるだろうか。本発表では、Isingモデルと画像データを通じて、主成分分析が物理学的にどのような意味があるかを議論する。
[2-R-061] 相対的公平性を実現する連合学習アルゴリズム
発表者 仲北祥悟 (東京大学), 金子竜也 (東京大学), 高前田伸也 (東京大学), 今泉允聡 (東京大学)
概要 連合学習におけるクライアント間のモデルの性能の公平性は、社会実装上重要な課題である。公平性の課題については、これまでワーストケースの性能を改善するミニマックス最適化問題としての定式化が提案されてきたが、これはクライアント間の相対的な性能の公平性を必ずしも実現しない。本発表では、クライアント間の相対的公平性を実現する最適化問題とアルゴリズムを提案し、その性質を検証する。
[2-R-062] 長距離相互作用する文脈依存言語における相転移現象 — 言語モデルの創発現象を統計力学の視点で理解する —
発表者 都地悠馬 (北大), 高橋惇 (東大), 横井祥 (東北大, 理研AIP), Vwani Roychowdhury (UCLA), 宮原英之 (北大)
概要 最近,大規模言語モデル (LLM) のスケーリング則 や創発的な能力が報告され,LLM のメカニズムを 理解する上で重要な手掛かりになることが期待され ている.実は統計力学においてもこれらの概念に相 当する「相転移」と呼ばれる概念が存在する.本研 究では,言語モデルの性質を相転移の観点で再検討 する.具体的には,長距離相互作用を持つ 1 次元イ ジング模型を念頭にした単純な言語モデルを構成 し,統計力学的な意味での相転移現象が起きること を示す.さらに,シンボル数が増えるという統計力 学モデルにはない言語モデル特有の過程に注目する ことで,統計力学モデルにはない現象を発見したこ とを報告する.
[2-R-063] 臨床試験における過去データ適応的利用のための重要度重み付き推定法
発表者 松井孝太 (名古屋大), 大東智洋 (東京理科大), 金森敬文 (東京科学大), 土田潤 (京都女子大), 坂巻顕太郎 (順天堂大)
概要 希少疾病などの臨床試験では,試験治療のデータのみを新規で集め,過去の試験の対照群との比較により治療効果を検討することがある.本研究では,このような単群試験において,平均処置効果を効率的に推定する重要度重み付き学習法を提案する.提案法は,密度比を用いて群間の共変量分布を揃えた比較を行い,症例単位で情報借用の程度を適応的に調整する.発表では推定量の理論的正当化と数値実験による評価を示す.
[2-R-064] データセット蒸留のためのKernel Inducing Pointsの一般化
発表者 ⻘⼭⻯也 (名古屋⼤学), 花⽥博幸 (理化学研究所), ⽥中智成 (名古屋⼤学), ⾚⽻智志 (名古屋⼤学), ⼤藏芳⽃ (名古屋⼤学), 橋本典明 (理化学研究所), 稲津佑 (名古屋⼯業⼤学), 李翰柱 (株式会社デンソー), 村⼭太朗 (株式会社デンソー), ⼩嶋信⽮ (株式会社デンソー), ⽵内⼀郎 (名古屋⼤学/理化学研究所)
概要 大規模データから小規模な合成データを作成する手法としてデータセット蒸留がある.データ蒸留法の多くは二重最適化問題になるため計算コストが高く様々な近似法が提案されている.リッジ回帰において効率的にデータ蒸留を行うKernel Inducing Points(KIP)と呼ばれる方法がある.本研究では,KIPを強凸最適化となる学習手法全般へ適用できるよう一般化する方法を提案する.これにより,例えば,回帰問題のみならず分類問題にも適用が可能となる.
[2-R-065] Information-theoretic Generalization Analysis for Expected Calibration Error
発表者 二見 太 (大阪大学,理研AIP), 藤澤将広 (理研AIP)
概要 While the expected calibration error (ECE), which employs binning, is widely adopted to evaluate the calibration performance of machine learning models, theoretical understanding of its estimation bias is limited. In this paper, we present the first comprehensive analysis of the estimation bias in the two common binning strategies, uniform mass and uniform width binning. Our analysis establishes upper bounds on the bias, achieving an improved convergence rate. Moreover, our bounds reveal, for the first time, the optimal number of bins to minimize the estimation bias. We further extend our bias analysis to generalization error analysis based on the information-theoretic approach, deriving upper bounds that enable the numerical evaluation of how small the ECE is for unknown data. Experiments using deep learning models show that our bounds are nonvacuous thanks to this information-theoretic generalization analysis approach.
[2-R-066] 不均衡分類問題での特徴量抽出におけるリウェイティング/リサンプリングの効果の解析
発表者 小渕智之 (京都大学), 田中利幸 (京都大学)
概要 不均衡分類問題における特徴量抽出の性能評価を行う目的で,データ生成モデルを2クラスの混合ガウスモデルとし,推定量をあるクラスの損失関数の最小化によって得る場合の統計力学的理論解析を行った.その結果,それぞれのクラスのデータ特徴量が等分散で,かつ推定にバイアスを含めない場合,損失関数や不均衡度合いに依らず,リウェイティング/リサンプリングを行わない場合に最も精度の良い推定となることを明らかにした.
[2-R-067] 局所近似による確率的最適化
発表者 星野力 (BIPROGY株式会社)
概要 報酬に不確実性を含む環境における確率的な探索に関して、局所的に近似した分布を使うアプローチについて考察する。
[2-R-068] アクティブラーニングを用いた悪性通信検知手法の検討
発表者 西山泰史 (NTTセキュリティホールディングス), 神谷和憲 (NTTセキュリティホールディングス)
概要 セキュリティログ分析では、ラベルのついた良性・悪性ログのデータは、熟練したアナリストが手作業で判断しなければならないため入手が難しい。また、攻撃者は検知の回避や手法の高度化を目的として、日々新たなマルウェアを生み出しているため、検知する分類器の更新が必要である。そこで、アクティブラーニングを用いて、ラベルのないデータから少量選択してラベル付けすることで、効率的に分類器を更新する手法について考える。
[2-R-069] 半教師あり学習による相乗的推論ネットワークを用いた画像領域分割の検証
発表者 中西慶一 (九工大), 徳永旭将 (九工大)
概要 深層学習による画像領域分割は, 教師データ作成のコストが高いことが課題である。我々は部分的な点注釈のみで訓練可能な領域分割フレームワーク: CoSPAを提案した。CoSPAは, 異なるネットワーク間の推論が未注釈画素に対しても整合性を持つよう訓練することで, 疎な点注釈データのみでネットワークを個別に訓練する以上の予測性能向上を実現した。本研究はこの整合性がもたらす相乗効果に着目し, その要因を検証する。
[2-R-070] マルコフ連鎖の代数的定式化に基づくモデル圧縮
発表者 小松優治 (名古屋大学), 北栄輔 (名古屋大学)
概要 ブラックボックス性の解消や計算量削減を目的として、モデル圧縮が盛んに研究されている。しかし、現状の圧縮手法はエッジの重み等の局所的な情報の利用にとどまり、全体の対称性や構造を十分に考慮していない。 本研究では、純粋に(余)代数的・圏論的な手法を用いてマルコフ連鎖を定義し、準同型性や極限等の概念を定式化する。これにより、マルコフ連鎖の圧縮を代数的に論じることが可能となる。さらに、簡単な応用例も示す。
[2-R-071] 双曲空間上で定義されるガウス過程潜在変数モデルを用いた階層構造の可視化
発表者 渡部 航史 (北海道大学), 前田 圭介 (北海道大学), 小川 貴弘 (北海道大学), 長谷山 美紀 (北海道大学)
概要 高次元データの2次元表現はデータ構造の理解に有効である.従来,低次元表現はユークリッド空間上で推定されてきたが,近年リーマン多様体を用いることで,特定の構造を効果的に推定できると報告されている.本研究では,双曲区間上で定義されるガウス過程潜在変数モデルを用いた階層構造の可視化手法を提案する.本手法を階層的な人工データと遺伝子発現データに適用し,階層構造の効果的な埋め込みが実現可能であることを示す.
[2-R-072] 信号時相論理式のベクトル埋め込みによるニューラル制御器の設計
発表者 橋本和宗 (大阪大学), 橋本航 (大阪大学), 岸田昌子 (国立情報学研究所), 高井重昌 (大阪大学)
概要 信号時相論理式は計算機科学の分野で提案された論理式であり、近年自動運転の安全性検証やロボットの経路タスクの仕様記述に用いられている。本発表では、信号時相論理式をベクトルに埋め込むことで、多様な制御仕様に対し汎用性を有する制御器設計手法を提案する。
[2-R-073] 関数近似器としてのニューラルネットワークと確率的摂動に対する安定性
発表者 秋山慧斗 (東北大学)
概要 中間層が1層のフィードフォワードニューラルネットワークは、普遍近似性を持ち、ニューロン数の逆平方根に比例する近似精度を持つ関数近似器である。この逆平方根オーダーは本質的に最良なものであることも知られている。本研究では、パラメータに確率的摂動を加えたニューラルネットワークが通常のものより高い性能を示す数値実験に注目し、逆平方根オーダーの近似精度を保つための確率的摂動のバウンドを定量的に評価した。
[2-R-074] Generalization Bound and Learning Methods for Data-Driven Projections in Linear Programming
発表者 坂上晋作 (東京大学, 理研AIP), 大城泰平 (北海道大学)
概要 How to solve high-dimensional linear programs (LPs) efficiently is a fundamental question. Recently, there has been a surge of interest in reducing LP sizes using “random projections,” which can accelerate solving LPs independently of improving LP solvers. We explore a new direction of “data-driven projections,” which use projection matrices learned from data instead of random projection matrices. Given training data of $n$-dimensional LPs, we learn an $n\times k$ projection matrix with $n > k$. When addressing a future LP instance, we reduce its dimensionality from $n$ to $k$ via the learned projection matrix, solve the resulting LP to obtain a $k$-dimensional solution, and apply the learned matrix to it to recover an $n$-dimensional solution. On the theoretical side, a natural question is: how much data is sufficient to ensure the quality of recovered solutions? We address this question based on the framework of data-driven algorithm design, which connects the amount of data sufficient for establishing generalization bounds to the pseudo-dimension of performance metrics. We obtain an $\tilde{O}(nk^2)$ upper bound on the pseudo-dimension, where $\tilde{O}$ compresses logarithmic factors. We also provide an $\Omega(nk)$ lower bound, implying our result is tight up to an $\tilde{O}(k)$ factor. On the practical side, we explore two simple methods for learning projection matrices: PCA- and gradient-based methods. While the former is relatively efficient, the latter can sometimes achieve better solution quality. Experiments demonstrate that learning projection matrices from data is indeed beneficial: it leads to significantly higher solution quality than the existing random projection while greatly reducing the time for solving LPs. This is a joint work with Taihei Oki and is to appear in NeurIPS 2024.
[2-R-075] Rectified Flowを用いた脈波からの心電位生成の検討
発表者 南部優太 (NTT人間情報研究所), 幸島匡宏 (NTT人間情報研究所), 山本隆二 (NTT人間情報研究所)
概要 2つの分布上の点を最短距離で結ぶ経路を学習することで画像を高速に生成可能な手法としてRectified Flowが注目されている。本研究では、脈波から心電位を生成する問題を対象として、Rectified Flowをベースに少ないステップ数で心電位を生成可能な手法を検討した。公開データセットを用いた実験の結果、本手法が拡散モデルベースの既存手法よりも高品質な心電位を高速に生成できることを確認した。
[2-R-076] 変分オートエンコーダの拡張による拡散生成モデルの導出
発表者 蒲健太郎 (東京科学大物理), 清水怜央 (東北大情報), 大関真之 (東京科学大物理, 東北大情報, シグマアイ), 杉山友規 (東北大情報)
概要 本研究では、拡散生成モデルを同じ尤度ベースモデルである変分オートエンコーダの拡張として捉え直すことで、スコアベース型やSB型拡散モデルの統一的な理解をもたらす理論を提案する。この理論を支えるのは、情報処理不等式が変数の数によらず成り立つという事実である。この結果は、既存の拡散モデルに対し解釈性の高い導出を与えるだけでなく、新たな生成モデルの構築の指針となることが期待される。
[2-R-077] 双方向市場における閲覧確率を考慮したオンラインランキング最適化
発表者 翁 啓翔 (株式会社リクルート), 西村 直樹 (株式会社リクルート), 小林 健 (東京科学大学), 中田 和秀 (東京科学大学)
概要 推薦システムにおいて、アイテムの表示位置がその後のアクションに大きく影響を及ぼすことが知られている。 特に双方向市場では双方のユーザに表示位置のバイアスが生じるために、単純な嗜好度順ではマッチング数の意味で全体最適なランキングにならないことが知られている。 本研究では片方のユーザが逐次的に訪問する双方向市場における最適な掲示順位の決定手法を提案する。
[2-R-078] 輸送による生成モデルの構築
発表者 清水怜央 (東北大情報), 蒲 健太郎 (東京科学大物理), 大関 真之 (東北大情報,東京科学大物理,シグマアイ), 杉山 友規 (東北大情報)
概要 近年常微分方程式(ODE)や確率微分方程式(SDE)に基づく連続時間生成モデルが高品質なデータを生成できるモデルとして注目されている. 本公演では,輸送による生成モデルの枠組みを提案し,その定式化において輸送を誘導するベクトル場と分布間距離関数のペアが重要な概念であることを見る. また,その枠組みにおいて既存のODE,SDEに基づく生成モデルの位置づけを明らかにする.
[2-R-079] Wカーネルとベイズ推定量の頻度論的評価
発表者 伊庭幸人 (統計数理研究所)
概要 各観測の対数尤度からなる行列とその固有空間がベイズ推定量の頻度論的性質の評価において重要な役割を持つことを議論する。この行列は再生カーネル(以下Wカーネル)と解釈でき、既存のFisherカーネルはその近似として理解できる。正則モデルではWカーネルの非零固有値に対応する空間はモデルの接空間のデータ空間での対応物となり、一般に固有値の和はWAICのバイアス補正項を与える。
[2-R-080] Exploring Collapse Phenomena in the Feature Space of Overparameterized Neural Networks for Imbalanced Regression through Unconstrained Feature Model
発表者 Chuang Ma (Kyoto University), Tomoyuki Obuchi (Kyoto University), Toshiyuki Tanaka (Kyoto University)
概要 In the feature space of over-parameterized neural networks, features tend to collapse into a simple geometric structure during the terminal phase of training, a phenomenon known as Neural Collapse (NC). This phenomenon has been extensively studied in recent years within the context of classification problems and has been applied to explain and address the challenges posed by imbalanced classification tasks. However, the collapse phenomenon in regression settings has rarely been explored. In this study, we utilize the Unconstrained Feature Model (UFM) to theoretically analyze and demonstrate that, under ideal conditions, the optimal feature representation of training data exhibits a similar collapse, where the features converge into a low-dimensional subspace aligned with the label space. Furthermore, we observe similar behavior in real neural network training. This research also investigates the relationship between the distribution of the label space and the collapse phenomenon in the context of deep imbalanced regression, exploring how this collapse can be leveraged to address the issue of label imbalance in regression tasks.
[2-R-081] 積和型重み最大経路探索問題とその応用
発表者 梶原秀太 (九州大学), Sherief Hashima (理研AIP), 畑埜晃平 (九州大学/理研AIP), 瀧本英二 (九州大学), 内澤啓 (山形大学)
概要 本発表では,5G/6G無線通信における問題の1つを積和型重み最大経路探索問題として定式化する.この問題はNP困難であること,また等価な混合整数計画問題をもつことを示す.さらに,行列積に基づく非自明なアルゴリズムを提案する.
[2-R-082] メタ学習に基づく少量データからの偏微分方程式の係数推定
発表者 熊谷拓 (京都大学), 岩田具治 (NTT), 田中利幸 (京都大学)
概要 Physics Informed Neural Networksは、ニューラルネットワークを使って偏微分方程式の解を近似する手法であり、方程式の未知係数を推定する逆問題にも適用できる。一方で、特にデータが少量しか得られない状況では解への収束の遅さ、精度の悪さといった問題が生じる。本研究では、少量のデータからでも効率的かつ精度良く方程式の未知係数を推定できるメタ学習手法を提案する。
[2-R-083] テスト分布外の訓練分布におけるノイズがテスト損失に与える影響の検証 (発表取消)
発表者 大坪悠介 ((株)日立製作所)
概要 計算資源の増大に伴い、より大きなニューラルネットワークをより大きなシミュレータからの生成データで訓練することが可能になってきている。このとき、シミュレータとしてどの程度の正確さが求められているかには疑問が残る。特に、運用時に活用される範囲のみ正確であれば良いのか、それとも運用時に活用されない範囲も含めて正確でなければ活用される範囲における汎化誤差も大きくなるのかをCIFAR10を用いて検証する。
[2-R-084] Bayesian generalized lasso正則化に基づくSVC回帰モデルの選択手法
発表者 書川 侑子 (総合研究大学院大学), 二宮 嘉行 (統計数理研究所)
概要 空間可変パラメータ(SVC)モデルに対してBayesian generalized lasso正則化を課すことで,隣接する地域に属する変数に対応する回帰係数どうしの差を縮小できる.正則化の課し方でモデルの複雑さが変化するが,WAICなどの従来の情報量規準は最も複雑なモデルを選択する.これを防ぐため,本研究では情報量規準PIICをSVCモデルに対し拡張する.数値実験を通し提案手法の有効性を検証する.
[2-R-085] 順序データのための近似的単峰尤度モデルの提案
発表者 山崎遼也 (一橋大)
概要 順序回帰は,離散目的変数Yが説明変数Xに対して自然な順序関係を持つような(X,Y)に従うデータ(順序データ)の分類問題である.先行研究により,順序データの多くで,Xの観測値を条件としたYの確率分布が単峰な傾向を持つと考えられる.本研究では,全ての単峰条件付き確率分布と単峰に近いものまでを表現できる尤度モデル(近似的単峰尤度モデル)を開発し,それに基づく順序回帰手法の有効性を数値実験で確認する.
[2-R-086] ニューラルネットワークにおけるブロック型勾配法の大域的収束性
発表者 秋山俊太 (CyberAgent)
概要 ニューラルネットワークの学習手法の一つとして,パラメータを層ごとに分け,それぞれを逐次的に更新するブロック型勾配法が知られている.ブロック型勾配法はその並列可能性や目的関数の単純化といった利点がある中で,停留点への収束保証しか与えられていなかった.本研究では,狭義単調増加な活性化関数およびReLU活性化関数に対して,ブロック型勾配法が大域的最適解へと収束することを理論的に保証した.
[2-R-087] Direct Distributional Optimization for Provable Alignment of Diffusion Models
発表者 川田遼太郎 (The University of Tokyo / AIP RIKEN), 大古一聡 (UC Berkeley / AIP RIKEN), 二反田 篤史 (A*STAR / Nanyang Technological University), 鈴木 大慈 (The University of Tokyo / AIP RIKEN)
概要 We introduce a novel alignment method for diffusion models from distribution optimization perspectives while providing rigorous convergence guarantees. We first formulate the problem as a generic regularized loss minimization over proba- bility distributions and directly optimize the distribution using the Dual Averaging method. Next, we enable sampling from the learned distribution by approximat- ing its score function via Doob’s h-transform technique. The proposed framework is supported by rigorous convergence guarantees and an end-to-end bound on the sampling error, which imply that when the original distribution’s score is known accurately, the complexity of sampling from shifted distributions is independent of isoperimetric conditions. This framework is broadly applicable to general distri- bution optimization problems, including alignment tasks in Reinforcement Learn- ing with Human Feedback (RLHF), Direct Preference Optimization (DPO), and Kahneman-Tversky Optimization (KTO). We empirically validate its performance on synthetic and image datasets using the DPO objective.
[2-R-088] 巡回Transformerの表現力について:理論的分析と時間依存特徴量による向上
発表者 Kevin Xu (東京大学), 佐藤一誠 (東京大学)
概要 We establish approximation rates of Looped Transformers by defining the concept of the modulus of continuity for sequence-to-sequence functions. This reveals a limitation specific to the looped architecture. That is, the analysis prompts us to incorporate scaling parameters for each loop, conditioned on timestep encoding.
[2-R-089] 未知の制約に対するニューラル制御バリア関数による安全性保証
発表者 平野皓己 (東京大学), 武石直也 (東京大学), 矢入健久 (東京大学)
概要 制御バリア関数を用いた制御は、システムが安全な状態を逸脱しないように制御入力を計算する手法である。従来の方法では、バリア関数の明示的な定式化が必要であったが、複雑なシステムでは困難である。そこで本研究では、シミュレーションを用いたデータ駆動型のアプローチで制御バリア関数を学習し、未知の制約条件下でも安全性を保証する手法を提案する。さらに、制御バリア関数の予測不確定性の定量化についても検討する。
[2-R-090] SE(3)不変な結晶構造モデリングにおけるフレームの役割の再考
発表者 伊藤優成 (オムロン サイニックエックス/大阪大学), 谷合竜典 (オムロン サイニックエックス), 五十嵐亮 (オムロン サイニックエックス), 牛久祥孝 (オムロン サイニックエックス), 小野寛太 (大阪大学)
概要 幾何学的グラフニューラルネットワークによる結晶構造のSE(3)不変なモデリングは材料情報学で重要である。SE(3)不変性を実現するアプローチの1つに「フレーム」がある。フレームは入力構造の向きを正規化するための座標系であるが、本研究では、この従来のフレームの考え方に一石を投じ、「動的フレーム」という概念を提案する。
[2-R-091] Task arithmeticにおける重み分離のための正則化手法の提案
発表者 吉田晃太朗 (Science Tokyo), 楢木悠二 (独立研究者), 堀江 孝文 (立命館大学), 山木良輔 (立命館大学,ProPlace), 清水良太郎 (ZOZO Research, UCSD), 斎藤侑輝 (ZOZO Research), Julian McAuley (UCSD), 長沼大樹 (UdeM,Mila,ProPlace)
概要 本研究では、task arithmeticの文脈で新たな正則化手法を提案する。まず、task vectorとモデルのヤコビ行列を基にした指標を導入し、これがタスク間の干渉に因果関係があることを示す。次に、この指標を最小化する正則化により、タスク間の干渉を大幅に軽減し、係数調整なしで精度を向上させる。また、将来のタスクが未知の環境下でも安定した性能を発揮することを確認した。
[2-R-092] Multiplicative Logit AdjustmentのNeural Collapseの観点による正当化
発表者 長谷川直哉 (東京大学)
概要 ロングテール認識における単純で有用なヒューリスティックの手法の一つとしてMultiplicative Logit Adjustment (MLA) がある.私たちはこのMLAの有効性を二段階の理論で保証した.まずNeural Collapseの理論に基づいて最適な分離平面を調整する理論を示し,次にMLAがその近似となることを示した.さらに,実験を通して現実的なサンプル数での有効性を検証した.
[2-R-093] Class-prior estimation and weakly-supervised kernel test for conditional independence
発表者 廣瀬雄士 (東京科学大学 情報理工学院), 金森敬文 (東京科学大学 情報理工学院/理研)
概要 Class-prior estimation (CPE) aims to estimate the class prior distribution in a mixture of class distributions. We address CPE in scenarios with positive unlabeled data or two sets of unlabeled data with different class priors. Most existing CPE methods rely on irreducibility or a similar assumption of non-overlapping support between class distributions. When these assumptions are violated, consistent CPE becomes impossible. We propose two novel assumptions for consistent CPE: conditional independence (CI) given class, and a more general CI assumption. These can hold even when irreducibility is not satisfied. We develop a method of moments estimators based on these CI assumptions and analyze their asymptotic behaviors. Additionally, we introduce a weakly-supervised kernel statistical test to validate CI assumptions from given data. Empirically, we show our proposed CPE methods perform well, and our tests can validate CI structure effectively.
[2-R-094] 高精度サンプリングアルゴリズム kernel herding の適用範囲の拡大
発表者 山下洋史 (大阪大学), 鈴木秀幸 (大阪大学)
概要 Herding はマルコフ連鎖モンテカルロ法に似たサンプリング手法で、ある種の関数の期待値の推定誤差がサンプル数Tに対してO(1/T)と高速に収束するため有用性が期待される。Kernel herding は対象の関数のクラスをカーネル法を用いて拡張したものであるが、現状では適用できる分布が混合ガウス分布などに限られている。本発表では、これをより広い分布に適用可能とするための手法について検討する。
[2-R-095] Zipf 白色化
発表者 横井祥 (東北大学, 理化学研究所), 包含 (京都大学), 栗田宙人 (東北大学), 下平英寿 (京都大学, 理化学研究所)
概要 単語の表現空間が歪んでいること、またこれを補正することで各種の言語処理タスクの性能が向上することが知られている。ただし、空間の歪みの度合いを測り補正する既存の手法群は暗黙的に単語頻度を一様と仮定しており、べき分布(いわゆるジップ則)に従う実際の単語頻度との乖離が大きい。本研究では、「期待値を計算する際は単語頻度を考慮すべし」という簡単な指針によって、既存手法よりもはるかに良好に空間の歪み測定・補正できることを報告する。また、既存手法と提案法を、指数型分布族の基底測度(base measure)が一様分布か経験分布かという視点で分類することで、白色化と分配関数の関係・単語埋め込みのノルムに乗る量・仮定している損失関数を一括して分類できることを述べる。また、スキップグラム(いわゆるword2vec)・WhiteningBERT・ヘッドレス言語モデルといった既存の手法群がなぜ高い性能を達成しているのかについても統一的な説明を与えることができる。
[2-R-096] Predict-then-Optimize に対する逆最適化アプローチ
発表者 引間泰成 (九州大学・富士通株式会社), 神山直之 (九州大学)
概要 現実の多くの問題は最適化問題として定式化されるが,最適化問題を構成するパラメータはしばしば事前には未知である.文脈付き逆最適化の目的は,未知パラメータに関連した特徴量と最適解がデータとして与えられる状況で,特徴量から未知パラメータを予測するモデルを構築することである.本研究では文脈付き逆最適化において,逆最適化問題をオラクルとしたアルゴリズムを提案し,既存の手法と比較を行った結果を報告する.
[2-R-097] 構成的なタスクにおけるTransformerモデルの学習過程の解析
発表者 高瀬侑亮 (京都大学), 本多淳也 (京都大学/理研), 下平英寿 (京都大学/理研)
概要 近年爆発的な成長を遂げている大規模言語モデルは、幅広い言語処理タスクで高い精度を達成している一方、グラフ推論や論理パズルといった逐次的な処理を必要とするタスクでは性能が劣ることが指摘されている。本研究では単純な処理を組み合わせた構成的なタスクが、Transformerモデル内でどのように学習されるかを観察する。そのために、各層での機能の獲得や段階的に処理能力が向上する過程に焦点を当てて解析する。
[2-R-098] 場の変形に基づく2次元離散分布間の最適輸送
発表者 奥 牧人 (富山大学)
概要 最適輸送(Wasserstein距離、アースムーバー距離)は様々な機械学習手法の中で使われる。点群でなく離散分布を使う場合、1次元以外では分布の変形過程を可視化しにくい。そこで本発表では、場の変形に基づく2次元離散分布間の最適輸送を提案する。比較対象の各分布と一様分布を対応付ける場をバブロイドアルゴリズムによる擬似拡散で求めることで、場から場への連続変形に対応した各時点の分布形状を計算出来る。
[2-R-099] ベイズリスク選好最適化:報酬モデル不要のオンライン選好最適化手法
発表者 森村哲郎 (サイバーエージェント), 坂本充生 (サイバーエージェント), 陣内佑 (サイバーエージェント), 阿部拳之 (サイバーエージェント), 蟻生開人 (サイバーエージェント)
概要 LLMを人間の選好にアラインメントする手法として,Direct Preference Optimization(DPO)が注目されている.しかし,固定された選好データセットに依存するため,分布シフトの問題がある.一方,Reinforcement Learning from Human Feedback(RLHF)は報酬モデルを用いたオンラインRLで分布シフトを軽減するが,報酬モデルへの依存性から過学習が起こりやすい.本研究はMinimum Bayes Risk(MBR)をDPOに統合し,報酬モデル不要のオンライン選好最適化フレームワークを提案し,有用性を実験的に検証する.
[2-R-100] 粒子型変分推論におけるLocal Entropyの適用
発表者 河村祐弥 (東京科学大学), 高邉 賢史 (東京科学大学)
概要 Stein Variational Gradient Descent (SVGD)は粒子型変分推論法として、サンプリング効率の高さと優れた収束性能で注目されている。しかし、多峰性確率分布の近似においては、粒子が局所的なモードに収束しやすい課題が存在する。本研究では、Local Entropyを適用して、多峰性確率分布をより正確に捉える新しい手法を提案する。計算機実験により、提案手法が近似性能が改善することを確認した。
[2-R-101] OpenCVを用いた金魚2個体の同時追跡
発表者 稲葉晴紀 (富山大学大学院理工学研究科), 壬生啓貴 (富山大学理学部), 松田恒平 (富山大学学術研究部理学系), 仲田崇人 (富山大学理学部), 木村巌 (富山大学学術研究部理学系), 上田肇一 (富山大学学術研究部理学系)
概要 2個体の金魚における社会性行動の解析を目的として、個々の金魚の頭の向きを正確に追跡するシステムの開発を試みた。金魚の行動解析には、オープンソースライブラリであるOpenCVを用い、画像処理を行った。個体の重なりや複雑な動きが生じる状況下でも、頭の向きを効果的に推定する手法を提案する。本アルゴリズムにより、2個体の金魚が重なった場合でもそれぞれの個体の位置と向きを復元することが可能となった。
[2-R-102] 位置符号化を利用しないTransformerによる階層的言語の認識・生成に関して
発表者 早川大地 (東京大学), 佐藤一誠 (東京大学)
概要 TransformerはRNNやLSTMなどの再帰型のモデルとは異なり,自然言語が有する階層的構造の理解が難しいと指摘されている.我々は,この否定的な結果と経験的な成功のギャップを埋めるため,階層的構造を抽象化したDyck言語を取り上げ,Transformerの表現力について分析する.具体的には,特定の位置符号化を仮定せずにDyck言語を認識・生成するTransformerが構成できることを示す.
[2-R-103] ブラックボックス最適化におけるMAP推定と確率的推定の比較
発表者 尾崎優太 (東京科学大学物理学系), 大関真之 (東京科学大学物理学系、東北大学情報科学研究科、株式会社シグマアイ)
概要 未知の関数形を持つ問題の最小化または最大化はブラックボックス最適化と呼ばれる。ブラックボックス最適化の手法には代理モデルを用いた方法があるが、代理モデルを機械学習によって設計する方法は様々である。組合せ構造を持つブラックボックス最適化では、代理モデルに2次多項式が用いられる。本研究では、このような代理モデルベースのブラックボックス最適化に対して、モデルパラメータの推定方法による違いを確認した。
[2-R-104] 外れ値に頑健な密度比推定
発表者 南雲亮佑 (総合研究大学院大学、パナソニックホールディングス株式会社), 藤澤洋徳 (統計数理研究所、総合研究大学院大学)
概要 外れ値に頑健な密度比推定の手法として Weighted DRE と gamma-DRE という手法を提案する.両手法は,外れ値に対する頑健性を得るために重み関数を導入することで二重強頑健性を持つ.二重強頑健性とは,密度比を構成する両方の分布に対して(二重),多くの外れ値が入っても(強),推定量が頑健であるという性質である.
[2-R-105] モデルブリッジ法を用いた交通シミュレーションデータ同化の高速化
発表者 重中秀介 (産業技術総合研究所), 西田 遼 (産業技術総合研究所), 山崎啓介 (産業技術総合研究所), 大西正輝 (産業技術総合研究所)
概要 数万台規模の車両の動きを扱う交通シミュレーションは実行に大きな計算が必要となり,少ないパラメータ数でも最適値の探索が困難となる.本発表では個々の車両動作の代わりに交通量のみを扱う簡略なシミュレーションを構成し,2つのシミュレーションの関係を学習するモデルブリッジ法を適用することで,超高速なパラメータ探索を実現する手法を紹介する.
[2-R-106] 密連想記憶の動特性
発表者 三村和史 (広島市立大学), 竹内純一 (九州大学)
概要 密連想記憶(model Aのモダンホップフィールドネット)の動特性を統計神経力学で解析する。
[2-R-107] Conformalised Conditional Normalising Flows for Joint Prediction Regions in time series
発表者 Eshant English (Institute of Statistical Mathematics, Hasso Plattner Institute), Christoph Lippert (Hasso Plattner Institute))
概要 Conformal Prediction offers a powerful framework for quantifying uncertainty in machine learning models, enabling the construction of prediction sets with finite-sample validity guarantees. While easily adaptable to non-probabilistic models, applying conformal prediction to probabilistic generative models, such as Normalising Flows is not straightforward. This work proposes a novel method to conformalise conditional normalising flows, specifically addressing the problem of obtaining prediction regions for multi-step time series forecasting. Our approach leverages the flexibility of normalising flows to generate potentially disjoint prediction regions, leading to improved predictive efficiency in the presence of potential multimodal predictive distributions.
[2-R-108] 波動運動論ハミルトニアンのデータ駆動型推定
発表者 本武陽一 (一橋大学), 佐々木真 (日本大学)
概要 核融合炉で観測されるミクロな乱流運動とマクロな帯状流の相互作用のような複雑な階層乱流現象のダイナミクスを、波動運動方程式と呼ばれる少数の自由度を持つハミルトニアン力学系としてモデル化することは、乱流の理解と制御を実現する上で有用である。本研究では、波動運動方程式に従う乱流運動をモデル化するハミルトニアンを推定するために、ニューラルネットワークを用いたデータ駆動型推定法を提案する。
[2-R-109] 波動方程式のハミルトニアン密度のDeepONetによる作用素学習
発表者 徐 百歌 (神戸大学大学院理学研究科), 田中 佑典 (NTTコミュニケーション科学基礎研究所), 松原 崇 (北海道大学大学院情報科学研究院), 谷口 隆晴 (神戸大学大学院理学研究科)
概要 ハミルトン力学の学習については,近年,Hamiltonian Neural Networksやその変種など,深層学習に基づく手法が盛んに研究されている.しかし,特に偏微分方程式を学習する場合,これらの手法はデータの離散化に依存しており,学習する際に,用いる微分作用素とその離散化の決定が必要となる.本研究では,波動方程式に対し,DeepONetを利用することで,そのような必要のないハミルトニアン密度の学習法を提案する.
[2-R-110] No-regret Bandit Exploration based on Soft Tree Ensemble Model
発表者 岩崎省吾 (LINEヤフー株式会社), 鈴村真矢 (LINEヤフー株式会社)
概要 We propose a novel stochastic bandit algorithm that employs reward estimates using a tree ensemble model. Specifically, our focus is on a soft tree model, a variant of the conventional decision tree that has undergone both practical and theoretical scrutiny in recent years. By deriving several non-trivial properties of soft trees, we extend the existing analytical techniques used for neural bandit algorithms to our soft tree-based algorithm. We demonstrate that our algorithm achieves a smaller cumulative regret compared to the existing ReLU-based neural bandit algorithms. We also show that this advantage comes with a trade-off: the hypothesis space of the soft tree ensemble model is more constrained than that of a ReLU-based neural network.
[2-R-111] Pair Swapping-based Sequence Optimization with Quantum Annealing
発表者 芳川昇之 (三菱電機株式会社)
概要 順序最適化問題をペア交換に基づく部分問題に変換することで、コスト関数をメトロポリスヘイスティングス法の提案分布に反映させ求解効率を向上させる手法を提案する。 コスト関数を反映させた提案分布からのサンプリングを行うことで最終的に得られる解の分散が小さくなることを確認した。
[2-R-112] 化学-空間情報に基づく情報理論的病態評価によるラマン分光組織学
発表者 近藤僚哉 (北海道大学), 水野雄太 (北海道大学), Jean Emmanuel Clement (北海道大学), 望月 健太郎 (京都府立医科大学), 原田 義規 (京都府立医科大学), 藤田克昌 (大阪大学), 小松崎民樹 (北海道大学)
概要 顕微ラマン分光法は多様な分子の空間分布を同時に計測することができるために化学情報による病理診断への応用が期待されている.多くの解析法は化学情報のみに基づいており,生体試料の空間情報を考慮していない.そこで空間情報を解析時に取り込むことにより詳しい病態の進行度合いを定量・予測する手法を提案する.ラマンスペクトル間の空間的局所不均一性を定量化する尺度に基づいて情報理論に依した分類手法を適用する.
エントリー
[2-E-01] Bayesian non-parametric inference for the spatiotemporal Hawkes process
発表者 牛源源 (統計数理研究所)
概要 Point process modeling is used to describe a series of discrete events that occur in a continuous temporal or spatiotemporal domain. Many temporal or spatiotemporal clustered point processes can be categorized as Hawkes self-exciting processes, which were first introduced by Alan G. Hawkes in 1971 and describe the excitation mechanisms among these discrete events. They have been shown to have wide applications in fields such as neuroscience, genome analysis, seismology, insurance, finance, and social sciences. The Hawkes process can be completely characterized by its conditional intensity function. Fitting a Hawkes process model to data requires estimating the conditional intensity function. Many previous methods, including parametric and non-parametric approaches, have certain limitations in quantifying uncertainty, as most estimation techniques provide only a point estimate for the conditional intensity function. Modeling the conditional intensity function in a Bayesian non-parametric way via a Gaussian Process (GP) prior allows us to incorporate prior knowledge and effectively encode the uncertainty of the quantities arising from data and prior information. Data augmentation helps us simplify an intractable likelihood and obtain a representation of the likelihood that is conjugate to the GP prior, which facilitates the construction of efficient Bayesian inference algorithms to derive the posterior distribution of the conditional intensity function.
[2-E-02] リプシッツネットワークの学習におけるリプシッツ定数の影響について
発表者 山下淳也 (名工大), 本谷秀堅 (名工大), 横田達也 (名工大)
概要 ニューラルネットワークは入力の微小な摂動に脆弱であり,頑健な学習モデルの発展が望まれている.ロバストなモデルとしてリプシッツネットワークが挙げられる.このモデルはリプシッツ定数を制限することで入力の摂動に対する出力の変動を抑えることが可能であり,敵対的事例に耐性を持つ.本発表ではL-リプシッツネットワークの簡単な実現方法と,Lによる分類精度とロバスト性の変化を示す.
[2-E-03] グラフ表現を用いたテンソルネットワーク分解のためのアルゴリズム
発表者 山本雅貴 (名古屋工業大学), 本谷秀堅 (名古屋工業大学), 横田達也 (名古屋工業大学)
概要 テンソルを、任意の構造のテンソルネットワーク(TN)に分解するために、MMアルゴリズムおよび交互最小二乗法を用いた最適化アルゴリズムを提案する。最適化アルゴリズムを適用する際の問題として、テンソル積などの計算方法がTNの構造によって異なることが挙げられる。そのため、グラフを用いてTNを表現することで、計算方法を自動的に決定できるアルゴリズムを構築する。
[2-E-04] リザバーコンピューティングを用いた系列データの重要度解析
発表者 山内大翔 (公立はこだて未来大学), 加藤譲 (公立はこだて未来大学)
概要 リザバーコンピューティング(RC)は、非線形力学系の再構成や予測における有効性と高性能のため、近年解析が進められている。本研究では時間遅延とLasso回帰を用いることで、出力と入力するダイナミクスの関係性を明らかにする。具体的には、非線形力学系におけるパラメータ推定時の重要度解析や、文章データの分類タスクにおいて、独立成分分析と組み合わせた各成分の重要度解析の数値計算結果を紹介する。
[2-E-05] 量子ダイナミクスをスパースに同定するための量子回路学習
発表者 立山雄晟 (公立はこだて未来大学), 加藤譲 (公立はこだて未来大学)
概要 非線形ダイナミクスの推定手法として非線形ダイナミクスのスパース同定( SINDy)があり、これは非線形ダイナミクスを基底関数で表現した係数をスパースに推定する。一方、量子古典ハイブリッド型の機械学習手法として量子回路学習が提案されている。本研究では、二つの手法を組み合わせた量子回路学習を用いたスパース同定( SIQDy)を提案し、量子スピンダイナミクスの推定を行った結果を示す。
[2-E-06] 組立ラインにおける隣接作業者の情報を相互参照する時系列行動セグメンテーション
発表者 森田亮 (コニカミノルタ株式会社), 香西諒也 (コニカミノルタ株式会社), 岸祐輔 (コニカミノルタ株式会社), 馬彦博 (コニカミノルタ株式会社)
概要 製造業の組立ラインでは、生産性向上のため時系列行動セグメンテーションによる作業解析が求められる。組立ラインでは、上流から下流へ組立対象物の受け渡しで作業者間の行動が相互に影響し合う。従来手法は単一動画に基づき単一作業者の推論を行うため前後工程の作業者行動情報を活用できない。本研究では隣接作業者の情報を相互参照し、複数作業者の時系列行動セグメンテーションを行うモデルについて検証を行った。
[2-E-07] アイテムの最小推薦割合を保証するユーザグループベースのオンラインバッチ推薦
発表者 小﨑礼 (北海道大学), 中村篤祥 (北海道大学)
概要 各アイテムの指定最小推薦割合を保証する、オンラインバッチ推薦問題FAIR-BATCH-MABを提案する。各ユーザグループに対するアイテムの推薦確率分布を決定し、バッチ処理で各ユーザへの推薦を行うことを繰り返す。バンディット方策による推定クリック率を用いて最適推薦確率分布を決定するFBOアルゴリズムを提案する。シミュレーションでは、トンプソンサンプリングを用いたFBOが高い性能を示した。
[2-E-08] テンソルネットワークの制約付き組合せ最適化への応用
発表者 神田慶樹 (慶應義塾大学), 服部智大 (慶應義塾大学), 中田百科 (リクルート, 慶應義塾大学), 田中宗 (慶應義塾大学)
概要 近年, 古典コンピュータでも量子状態を近似的に扱えるテンソルネットワークを組合せ最適化問題に応用する研究が注目されている. 本研究では, 制約条件を満たす状態を表すテンソルネットワークを機械的に構成することで、組合せ最適化問題を効率的に解くという先行研究の手法の優位性および拡張性を検証する. 具体的には, ペナルティ法に対して比較実験を行った. また, 先行研究の手法の計算効率向上の可能性について模索する.
[2-E-09] 非有界雑音下の線形システムに対するオンライン最適制御のリグレット解析
発表者 伊藤海斗 (東京大学), 土屋平 (東京大学)
概要 オンライン最適制御は,制御対象システムに混入する雑音と将来のコスト関数が未知なもと,累積制御コストのリグレット最小化を行う枠組みである.線形システムのオンライン制御は様々な設定でリグレット上界が知られているが,共通して雑音の有界性が仮定されており,外れ値を考慮するのに適していない.本研究は,雑音のモーメント有界性や劣ガウス性のもとで,有界雑音と同様のリグレット上界が高確率で達成できることを示す.
[2-E-10] Sim2Real転移学習による触媒活性予測
発表者 矢作裕太 (NEC, 産総研), 小渕喜一 (NEC, 産総研), 高坂文彦 (産総研), 松井孝太 (名大)
概要 Sim2Real転移学習は、材料分野における少データ問題解決策として注目を集めている。我々は、第一原理計算データから実験データへと知識を転移することで、触媒活性予測の精度を向上させる手法を提案した。本手法は計算から実験へのドメイン変換と、同質ドメイン間の転移学習の2段階からなる。本手法の適用により少数(10未満)のターゲットデータで高い予測精度が達成され、本手法が実験回数の削減に有効であることが確認された。
[2-E-11] Multi-modal cascade feature transfer for polymer property prediction
発表者 小渕喜一 (NEC&産総研), 矢作裕太 (NEC&産総研), 當山清彦 (NEC), 田中修吉 (NEC), 松井孝太 (名古屋大学)
概要 本稿では、ポリマー特性予測の精度向上を目的とした、特徴転移によるマルチモーダルカスケードモデルを提案する。ポリマーは、分子記述子や添加物情報、化学構造など、複数の形式でデータが構成される。我々のモデルは、GCNにより抽出された化学構造の特徴を分子記述子や添加物情報と組み合わせるモデルであり、複数のポリマーデータセットを用いた実験により、本手法が従来手法と比較して高い予測性能を示したことを報告する。
[2-E-12] 拡散モデルを用いた疑似異常データ生成手法
発表者 不死原大知 (NTT), 橋本悠香 (NTT), 松尾洋一 (NTT)
概要 通信ネットワークの異常検知では, 異常データが少ないため機械学習モデルの適用が難しいという課題がある. 本研究では, この課題を解決するため, 拡散モデルを用いて疑似異常データを生成する手法を提案する. 具体的には, 拡散モデルの逆拡散過程を条件付き変分オートエンコーダ(CVAE)でモデル化し, 学習後にCVAEの潜在変数として外れ値をサンプリングすることで, 疑似異常データを生成する.
[2-E-13] 異なる事前学習済みモデルにおけるLoRAを用いたタスク算術
発表者 遠藤温広 (千葉大), 計良宥志 (千葉大), 川本一彦 (千葉大)
概要 異なるパラメータを持つ事前学習済みモデルに対し,低ランク補正LoRAを用いたタスク算術手法を提案する.課題は異なるモデルに対するLoRA出力が小さく,算術後の出力が元のモデルのままになってしまうことである.そこでLoRAに正規直交変換を導入しベクトルの方向を調整し問題を緩和する.従来のタスク算術は同一パラメータのモデルに限られていたが,提案手法により低コストでマルチタスクモデルを構築できる.
[2-E-14] フォンミーゼス・フィッシャー分布を用いた異常検知手法の風向への適用
発表者 横堀佑也 (三井住友海上火災保険株式会社), 石川雅之 (三井住友海上火災保険株式会社)
概要 方向データに対する異常検知の手法として、フォンミーゼス・フィッシャー分布を用いて異常度を評価する手法が知られている。本研究では、方向データである日本の風向データに対して、フォンミーゼス・フィッシャー分布を用いた異常検知手法を適用し、その適用結果と風向に対する異常検知の適用可能性について議論する。
[2-E-15] Geometric Resampling in Nearly Linear Time for Follow-The-Perturbed-Leader
発表者 Botao Chen (Kyoto University), Junya Honda (Kyoto University / RIKEN)
概要 In multi-armed bandit problems, it has been proved that Follow-The-Perturbed-Leader (FTPL) policy achieves both O(sqrt{KT}) regret for adversarial setting and a logarithmic regret for stochastic setting. In FTPL policy, the arm-selection probability has no analytical solution and we use its estimator by the technique called Geometric Resampling (GR). In the known algorithm of GR, however, the computational cost of sampling at each round is O(K^2), which is worse than other standard policies. In this work, we improve GR by sampling from a specific conditional distribution, which increases the probability of termination. Then, an unbiased estimate of arm-selection probability can be obtained through simple probability calculations. This improvement reduces the computational cost from O(K^2) to O(KlogK), significantly saving computational resources. We also discuss other possibilities of the improvement of FTPL with GR.
[2-E-16] StrWAEs to Invariant Representations
発表者 LEE HYUNJONG (The University of Tokyo)
概要 Autoencoders have become an indispensable tool for generative modeling and representation learning in high dimensions. Imposing structural constraints such as conditional independence in order to capture invariance of latent variables to nuisance information has been attempted through adding ad hoc penalties to the loss function mostly in the variational autoencoder (VAE) context, often based on heuristics. This paper demonstrates that Wasserstein autoencoders (WAEs) are highly flexible in embracing such structural constraints. Well-known extensions of VAEs for this purpose are gracefully handled within the framework of WAEs. In particular, given a conditional independence structure of the generative model (decoder), corresponding encoder structure and penalties are derived from the functional constraints that define the WAE. These structural uses of WAEs, termed StrWAEs (“stairways”), open up a principled way of penalizing autoencoders to impose structural constraints. Utilizing these advantages, we present a handful of results on semi-supervised classification, conditional generation, and invariant representation tasks.
[2-E-17] Accuracy-Preserving Calibration via Statistical Modeling on Probability Simplex
発表者 江崎 泰志 (豊田中央研究所), 中村 亮裕 (豊田中央研究所), 河野 圭祐 (豊田中央研究所), 徳久 良子 (豊田中央研究所), 沓名 拓郎 (豊田中央研究所)
概要 Classification models based on deep neural networks (DNNs) must be calibrated to measure the reliability of predictions. Some recent calibration methods have employed a probabilistic model on the probability simplex. However, these calibration methods cannot preserve the accuracy of pre-trained models, even those with a high classification accuracy. We propose an accuracy-preserving calibration method using the Concrete distribution as the probabilistic model on the probability simplex. We theoretically prove that a DNN model trained on cross-entropy loss has optimality as the parameter of the Concrete distribution. We also propose an efficient method that synthetically generates samples for training probabilistic models on the probability simplex. We demonstrate that the proposed method can outperform previous methods in accuracy-preserving calibration tasks using benchmarks.
ポスター配置図
ポスターセッション1(11月5日(火))
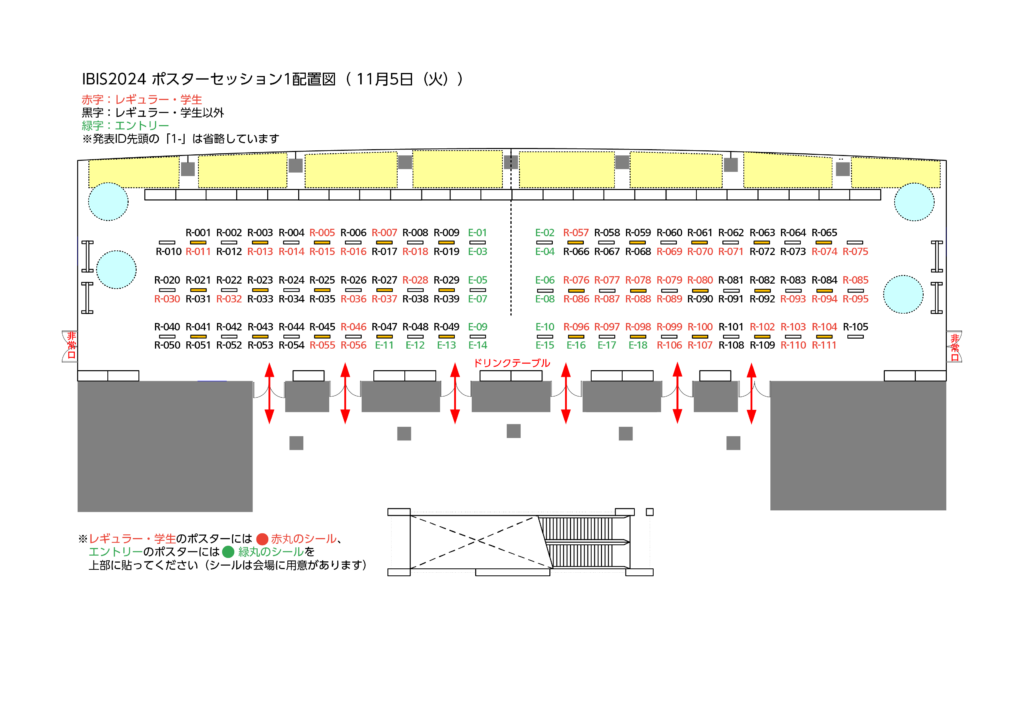
ポスターセッション2(11月6日(水))